filmov
tv
How to Extract Data from Twitter Without Coding

Показать описание
✨What is a web crawler?
✨How does a web crawler work?
✨What are the differences between it and a web scraper?
Get yourself refilled with all info related!
In this web scraping tutorial, I’ll show you how to scrape Twitter data in 5 minutes without using Twitter API, Tweepy, Python, or writing a single line of code.
As Octoparse simulates human interaction with a webpage, it allows you to pull all the information you see on any website, such as Twitter. For example, you can easily extract Tweets of a handler, tweets containing certain hashtags, or posted within a specific time frame, etc.
All you need to do is to grab the URL of your target webpage and paste it into Octoparse built-in browser. Within a few point-and-clicks, you will be able to create a crawler from scratch by yourself. When the extraction is completed, you can export the data into Excel sheets, CSV, HTML, SQL, or you can stream it into your database in real-time via Octoparse APIs.
Step 1: Input the URL and build a pagination 1:24
Twitter applies “Infinite scrolling” technique, which means that you need to first scroll down the page to let Twitter load a few more tweets, and then extract the data shown on the screen.
Step 2: Build a loop item to extract the data 2:28
Make sure you go into the action setting of the “extract data” step. Click on the handler, and click “extract the text of the selected element”. Repeat this action to get all the data fields you want.
Step 3: Modify the pagination setting and execute the crawler 4:03
As we want Twitter to load the content fully before the bot extracts it, let’s set up the AJAX time out as 5 seconds, to give Twitter 5 seconds to load after each scroll.
Then, set up both the scroll repeats and the wait time as 2 to make sure that Twitter loads the content successfully. Now, for each scroll, Octoparse will scroll down for 2 screens, and each screen will take 2 seconds.
Head back to the loop item setting to edit the loop time to 20. This means that the bot will repeat the scrolling for 20 times.
Check out our Help Center for all web scraping tutorials
***About Us***
Octoparse data extraction: is a #webscrapingtool #webcrawler specifically designed for scalable data extraction of various data types. It can harvest URLs, phone, email addresses, product pricing, reviews, as well as meta tag information and body text. Octoparse is a SIMPLE but POWERFUL web scraping tool for harvesting structured information and specific data types related to the keywords you provide by searching through multiple layers of websites.
*** FREE TRIAL ***
Start FREE-14-Day Trial
Start FREE-30-Day Enterprise Trial
*** FOLLOW TEAM ! ***
Skype: Octoparse
#Twitterscraper #Twitterextractor
✨How does a web crawler work?
✨What are the differences between it and a web scraper?
Get yourself refilled with all info related!
In this web scraping tutorial, I’ll show you how to scrape Twitter data in 5 minutes without using Twitter API, Tweepy, Python, or writing a single line of code.
As Octoparse simulates human interaction with a webpage, it allows you to pull all the information you see on any website, such as Twitter. For example, you can easily extract Tweets of a handler, tweets containing certain hashtags, or posted within a specific time frame, etc.
All you need to do is to grab the URL of your target webpage and paste it into Octoparse built-in browser. Within a few point-and-clicks, you will be able to create a crawler from scratch by yourself. When the extraction is completed, you can export the data into Excel sheets, CSV, HTML, SQL, or you can stream it into your database in real-time via Octoparse APIs.
Step 1: Input the URL and build a pagination 1:24
Twitter applies “Infinite scrolling” technique, which means that you need to first scroll down the page to let Twitter load a few more tweets, and then extract the data shown on the screen.
Step 2: Build a loop item to extract the data 2:28
Make sure you go into the action setting of the “extract data” step. Click on the handler, and click “extract the text of the selected element”. Repeat this action to get all the data fields you want.
Step 3: Modify the pagination setting and execute the crawler 4:03
As we want Twitter to load the content fully before the bot extracts it, let’s set up the AJAX time out as 5 seconds, to give Twitter 5 seconds to load after each scroll.
Then, set up both the scroll repeats and the wait time as 2 to make sure that Twitter loads the content successfully. Now, for each scroll, Octoparse will scroll down for 2 screens, and each screen will take 2 seconds.
Head back to the loop item setting to edit the loop time to 20. This means that the bot will repeat the scrolling for 20 times.
Check out our Help Center for all web scraping tutorials
***About Us***
Octoparse data extraction: is a #webscrapingtool #webcrawler specifically designed for scalable data extraction of various data types. It can harvest URLs, phone, email addresses, product pricing, reviews, as well as meta tag information and body text. Octoparse is a SIMPLE but POWERFUL web scraping tool for harvesting structured information and specific data types related to the keywords you provide by searching through multiple layers of websites.
*** FREE TRIAL ***
Start FREE-14-Day Trial
Start FREE-30-Day Enterprise Trial
*** FOLLOW TEAM ! ***
Skype: Octoparse
#Twitterscraper #Twitterextractor
 0:05:32
0:05:32
How To Extract Data From Excel Spreadsheet
 0:04:11
0:04:11
How to Extract Data from ANY Website to Excel
 0:08:34
0:08:34
Extract Data to Separate Sheets the Right Way!
 0:05:53
0:05:53
VLookUp - How To Extract Data From an Excel Spreadsheet Given Customer ID Number
 0:04:30
0:04:30
Extract Specific Data from PDF to Excel
 0:39:39
0:39:39
The Ultimate Scraper Tutorial | Extract Data Without Code
 0:15:54
0:15:54
How to Extract Data from a Spreadsheet using VLOOKUP, MATCH and INDEX
 0:05:09
0:05:09
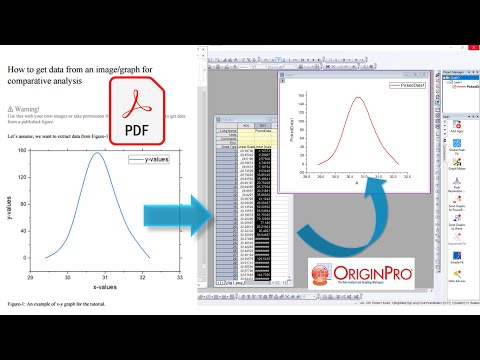
How to get (extract) data from graph (image) | Image digitizer | OriginPro
 0:13:15
0:13:15
Extract PDF Content with Python
 0:00:31
0:00:31
Excel Pro Tip: How to Easily Extract Numbers from Cells
 0:29:30
0:29:30
How to Extract Data from PDF with Power Automate
 0:05:33
0:05:33
How to Extract Data from Website to Excel Automatically (Tutorial 2020)
 0:09:40
0:09:40
Microsoft AI Builder Tutorial - Extract Data from PDF
 0:04:38
0:04:38
Scrape Data from Any Website with Browse Ai | Extract any data from any website
 0:07:25
0:07:25
Extract Data from PDFs Easily & Quickly (table form/image/text/pages)
 0:05:32
0:05:32
How to Extract Data from Twitter Without Coding
 0:05:40
0:05:40
How to Extract Data from Twitter using Python [Tweepy API]
 0:12:16
0:12:16
How to Extract Data from ANY Website to CSV
 0:07:52
0:07:52
PlotDigitizer - How to Automatically Extract Data from Graph Image (#3)
 0:00:38
0:00:38
How to Extract Table Data from PDF to Excel
 0:16:43
0:16:43
How to Extract Part of Text String from an Excel Cell
 0:06:45
0:06:45
How to Extract Data in Excel with Advance Filter VBA step by step
 0:03:30
0:03:30
How to Extract Data from Research Papers for Review Paper
 0:02:26
0:02:26
Extract Data from SQL Databases with Python
Комментарии