filmov
tv
Parallel inferencing with KServe Ray integration

Показать описание
KServe is a Opensource production-ready model inference framework on Kubernetes utilizing many knative's features such as routing for canary traffic and payload logging. However, the one model per container paradigm limits the concurrency and throughput when sending multiple inference requests. With RayServe integration, a model can be deployed as individual Python workers allowing for parallel inference. This enables concurrent inference requests to be processed simultaneously, improving overall efficiency. In this talk, we will share how you can configure, run, and scale machine learning models in Kubernetes using KServe and Ray.
About Anyscale
---
Anyscale is the AI Application Platform for developing, running, and scaling AI.
If you're interested in a managed Ray service, check out:
About Ray
---
Ray is the most popular open source framework for scaling and productionizing AI workloads. From Generative AI and LLMs to computer vision, Ray powers the world’s most ambitious AI workloads.
#llm #machinelearning #ray #deeplearning #distributedsystems #python #genai
About Anyscale
---
Anyscale is the AI Application Platform for developing, running, and scaling AI.
If you're interested in a managed Ray service, check out:
About Ray
---
Ray is the most popular open source framework for scaling and productionizing AI workloads. From Generative AI and LLMs to computer vision, Ray powers the world’s most ambitious AI workloads.
#llm #machinelearning #ray #deeplearning #distributedsystems #python #genai
 0:07:43
0:07:43
Parallel inferencing with KServe Ray integration
 0:30:28
0:30:28
Enabling Cost-Efficient LLM Serving with Ray Serve
 0:37:37
0:37:37
Serverless Machine Learning Model Inference on Kubernetes with KServe by Stavros Kontopoulos
 0:28:08
0:28:08
Exploring ML Model Serving with KServe (with fun drawings) - Alexa Nicole Griffith, Bloomberg
 0:30:00
0:30:00
Accelerate Federated Learning Model Deployment with KServe (KFServing) - Fangchi Wang & Jiahao C...
 0:25:10
0:25:10
How We Built an ML inference Platform with Knative - Dan Sun, Bloomberg LP & Animesh Singh, IBM
 0:32:34
0:32:34
Ray Serve: Tutorial for Building Real Time Inference Pipelines
 0:04:03
0:04:03
Open-source Chassis.ml - Deploy Model to KServe
 0:32:07
0:32:07
Fast LLM Serving with vLLM and PagedAttention
 0:11:53
0:11:53
Go Production: ⚡️ Super FAST LLM (API) Serving with vLLM !!!
 0:25:42
0:25:42
Deploying Many Models Efficiently with Ray Serve
 0:28:04
0:28:04
Faster and Cheaper Offline Batch Inference with Ray
 0:21:09
0:21:09
Kubeflow Essentials 7-2. Kserve (Architecture Concepts)
 0:30:19
0:30:19
How to Create a Custom Serving Runtime in KServe ModelMesh to S... Rafael Vasquez & Christian Ka...
 0:48:34
0:48:34
Serving Machine Learning Models at Scale Using KServe - Animesh Singh, IBM - KubeCon North America
 0:12:17
0:12:17
modelcar-demo
 0:23:03
0:23:03
Introducing Ray Serve: Scalable and Programmable ML Serving Framework - Simon Mo, Anyscale
 0:36:11
0:36:11
What's New, ModelMesh? Model Serving at Scale - Rafael Vasquez, IBM
 0:31:13
0:31:13
Serving Machine Learning Models at Scale Using KServe - Yuzhui Liu, Bloomberg
 0:35:53
0:35:53
Accelerating LLM Inference with vLLM
 0:25:12
0:25:12
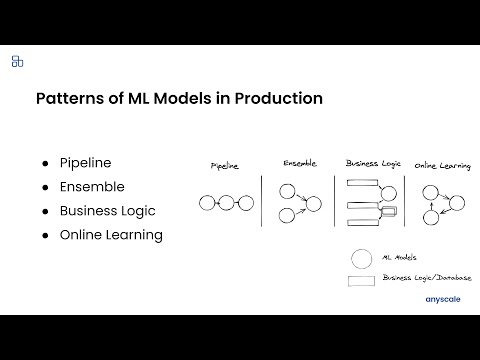
Ray Serve: Patterns of ML Models in Production
 0:32:24
0:32:24
Inference Graphs at LinkedIn Using Ray-Serve
 0:24:27
0:24:27
KServe: The State and Future of Cloud Native Model Serving (Kubeflow Summit 2022)
 0:14:19
0:14:19
Custom Code Deployment with KServe and Seldon Core
Комментарии