filmov
tv
Extract tabular data from PDF with Python - Tabula, Camelot, PyPDF2
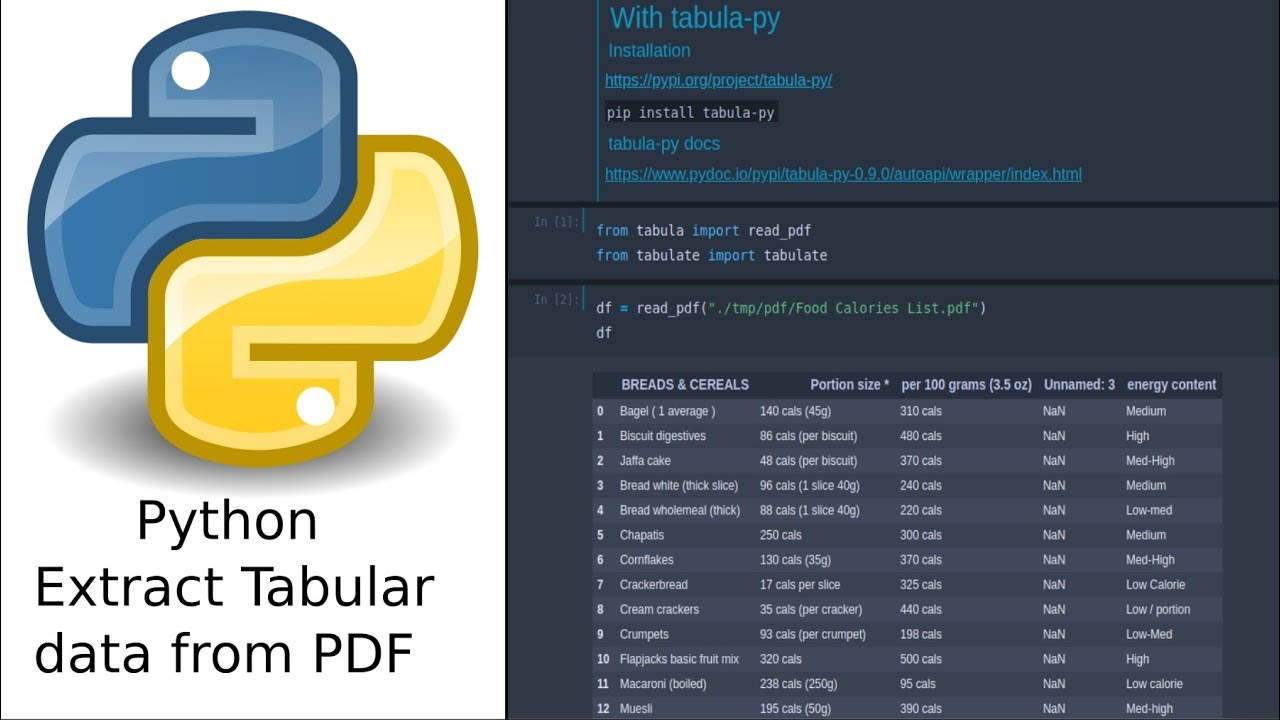
Показать описание
Code
PDF example 1
PDF example 2
Survey Stack OverFlow
Survey Jetbrains
0:00: intro
1:50: Extract table from PDF with Tabula
7:48: Extract PDF tables with Camelot
9:07: pasrse PDF table - PyPDF2
---------------------------------------------------------------------------------------------------------------------------------------------------------------
Code store
Socials
If you really find this channel useful and enjoy the content, you're welcome to support me and this channel with a small donation via PayPal.
PDF example 1
PDF example 2
Survey Stack OverFlow
Survey Jetbrains
0:00: intro
1:50: Extract table from PDF with Tabula
7:48: Extract PDF tables with Camelot
9:07: pasrse PDF table - PyPDF2
---------------------------------------------------------------------------------------------------------------------------------------------------------------
Code store
Socials
If you really find this channel useful and enjoy the content, you're welcome to support me and this channel with a small donation via PayPal.
 0:10:41
0:10:41
Extract tabular data from PDF with Python - Tabula, Camelot, PyPDF2
 0:00:30
0:00:30
How to copy table from PDF to Excel File in 30seconds
 0:14:07
0:14:07
How to Extract Tables from PDF using Python
 0:08:21
0:08:21
Extract Tables from PDFs
 0:08:06
0:08:06
Best Way to Extract Tables from PDF with LLMs
 0:09:40
0:09:40
How to 'automatically' extract data from a messy PDF table to Excel
 0:17:00
0:17:00
Extract text, links, images, tables from Pdf with Python | PyMuPDF, PyPdf, PdfPlumber tutorial
 0:18:28
0:18:28
Extract Table Info From PDF & Summarise It Using Llama3 via Ollama | LangChain
 0:32:41
0:32:41
Automate Insight Extraction process from customer feedback using Generative AI & AWS
 0:07:25
0:07:25
Extract Data from PDFs Easily & Quickly (table form/image/text/pages)
 0:03:40
0:03:40
Extract All the Tables From PDF in 3 minutes With Python
 0:00:38
0:00:38
How to Extract Table Data from PDF to Excel
![[15] Use Python](https://i.ytimg.com/vi/eTz3VZmNPSE/hqdefault.jpg) 0:18:17
0:18:17
[15] Use Python to extract invoice lines from a semistructured PDF AP Report
 0:09:40
0:09:40
Microsoft AI Builder Tutorial - Extract Data from PDF
 0:00:16
0:00:16
PDF Extractor SDK - C# - Extract Table Structure
 0:01:08
0:01:08
How to extract data from PDF document into XLS, CSV and other tabular formats
 0:03:59
0:03:59
Extract Tabular Data from PDF Using pdfplumber
 0:03:15
0:03:15
How to Extract Table from PDF to Office Efficiently
 0:05:16
0:05:16
Extract Tabular Data From PDF.
 0:03:33
0:03:33
How to Extract Table from PDF using Power Automate | Power Automate Tutorial
 0:13:15
0:13:15
Extract PDF Content with Python
 0:29:10
0:29:10
Extract tabular Data from PDF using AI Builder Form Processing in Power apps
 0:39:17
0:39:17
Extract and Visualize Data from PDF Tables with PDFplumber in Python
 0:15:41
0:15:41
Extract Tables from PDFs & Images - Convert PDF to Excel using Camelot in Python
Комментарии