filmov
tv
Extract and Visualize Data from PDF Tables with PDFplumber in Python

Показать описание
By using PDFplumber, I was able to create a graph which shows the trend at the center of my article. I hope some of you can take something away from this walkthrough that will help you supplement your own reporting, especially if you're interested in data journalism.
I'm by no means an expert coder, very much a beginner, so if there are things I could have done better let me know. That being said, I hope this walkthrough proves that any journalist can use programming to enhance their work, so you should try it if you haven't already!
#python #walkthrough #journalism
Extract and Visualize Data from PDF Tables with PDFplumber in Python
 0:41:17
0:41:17
Extract and Visualize Data from URLs using Unfurl w/ Ryan Benson - SANS DFIR Summit 2020
 0:27:21
0:27:21
Data Visualization Tutorial For Beginners | Big Data Analytics Tutorial | Simplilearn
 0:07:09
0:07:09
Science of Data Visualization | Bar, scatter plot, line, histograms, pie, box plots, bubble chart
 0:40:03
0:40:03
Jorge De la Cruz | How to Consume, Extract and Visualize Data with InfluxDB & Grafana | InfluxDa...
 0:04:06
0:04:06
Coronavirus Data Extraction & Visualization (COVID-19)
 0:36:11
0:36:11
Visualization Step-By-Step Series: Part 2 - Extracting data
 0:12:05
0:12:05
Extract & Visualize Data with ChatGPT: OCR Analysis Magic!
 0:03:28
0:03:28
Power BI Experience 05
 0:09:22
0:09:22
Build with Me: Visualize Data using Amazon QuickSight | AWS Project
 1:09:34
1:09:34
Python Project to Scrape YouTube using YouTube Data API | Analyze and Visualize YouTube data
 0:14:48
0:14:48
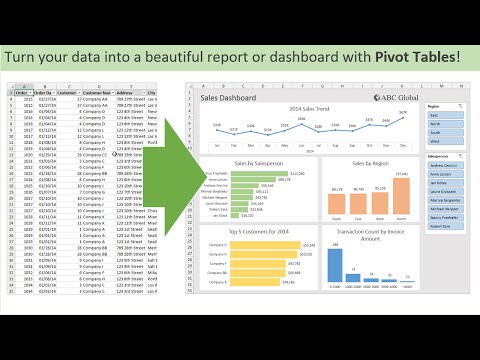
Introduction to Pivot Tables, Charts, and Dashboards in Excel (Part 1)
 0:09:42
0:09:42
How to find connected papers and visualize them in an interactive graph
 0:10:20
0:10:20
A Beginners Guide To The Data Analysis Process
 0:02:20
0:02:20
D3.js in 100 Seconds
 0:16:08
0:16:08
Extract any stock's data and visualize the data using Python (No need to install Python or a ID...
 0:44:56
0:44:56
#18 ABAQUS Tutorial: Visualization and extracting results in ABAQUS
 0:21:00
0:21:00
Real Data Visualization with Python, matplotlib, numpy, pandas
 0:47:14
0:47:14
Data Visualization | Data Visualization Python | Intellipaat
 0:26:51
0:26:51
ggplot for plots and graphs. An introduction to data visualization using R programming
 0:43:20
0:43:20
RESTful APIs – How to Consume, Extract, Store and Visualize Data with InfluxDB and Grafana
 0:16:31
0:16:31
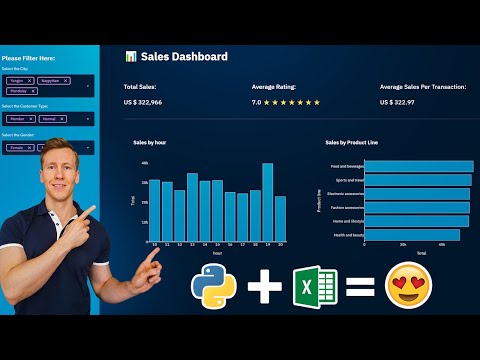
Turn An Excel Sheet Into An Interactive Dashboard Using Python (Streamlit)
 0:07:03
0:07:03
Extract web data with import.io and create d3 visualization
 0:14:38
0:14:38
273 Crowdsourcing based Data Extraction from Visualization Charts
Комментарии