filmov
tv
Lesson 5: Practical Deep Learning for Coders 2022
Показать описание
00:00:00 - Introduction
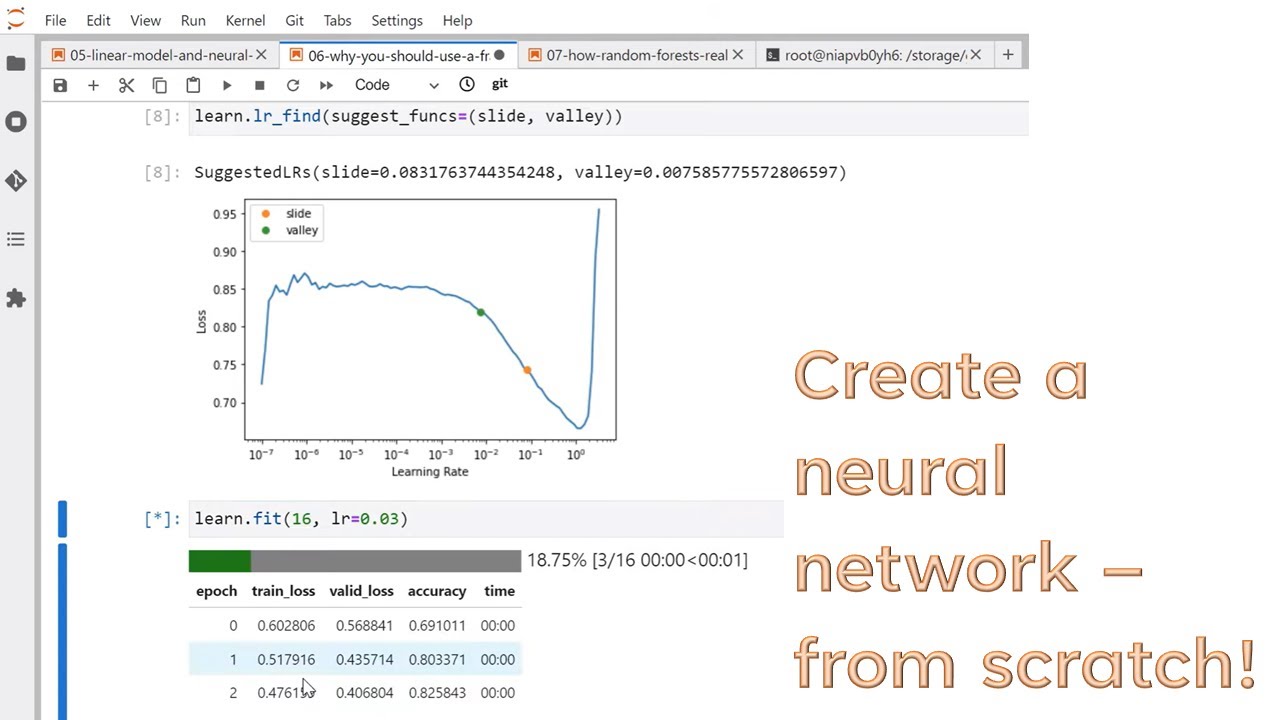
00:01:59 - Linear model and neural net from scratch
00:07:30 - Cleaning the data
00:26:46 - Setting up a linear model
00:38:48 - Creating functions
00:39:39 - Doing a gradient descent step
00:42:15 - Training the linear model
00:46:05 - Measuring accuracy
00:48:10 - Using sigmoid
00:56:09 - Submitting to Kaggle
00:58:25 - Using matrix product
01:03:31 - A neural network
01:09:20 - Deep learning
01:12:10 - Linear model final thoughts
01:15:30 - Why you should use a framework
01:16:33 - Prep the data
01:19:38 - Train the model
01:21:34 - Submit to Kaggle
01:23:22 - Ensembling
01:25:08 - Framework final thoughts
01:26:44 - How random forests really work
01:28:57 - Data preprocessing
01:30:56 - Binary splits
01:41:34 - Final Roundup
00:01:59 - Linear model and neural net from scratch
00:07:30 - Cleaning the data
00:26:46 - Setting up a linear model
00:38:48 - Creating functions
00:39:39 - Doing a gradient descent step
00:42:15 - Training the linear model
00:46:05 - Measuring accuracy
00:48:10 - Using sigmoid
00:56:09 - Submitting to Kaggle
00:58:25 - Using matrix product
01:03:31 - A neural network
01:09:20 - Deep learning
01:12:10 - Linear model final thoughts
01:15:30 - Why you should use a framework
01:16:33 - Prep the data
01:19:38 - Train the model
01:21:34 - Submit to Kaggle
01:23:22 - Ensembling
01:25:08 - Framework final thoughts
01:26:44 - How random forests really work
01:28:57 - Data preprocessing
01:30:56 - Binary splits
01:41:34 - Final Roundup
 1:42:49
1:42:49
Lesson 5: Practical Deep Learning for Coders 2022
 2:03:04
2:03:04
Lesson 5: Practical Deep Learning for Coders
 2:18:39
2:18:39
Lesson 5: Deep Learning 2018
 3:38:31
3:38:31
Practical Deep Learning for Coders - Lesson 5 - Part 1
 1:44:47
1:44:47
Practical Deep Learning for Coders - Lesson 5 - Part 2
 11:12:32
11:12:32
Practical Deep Learning for Coders - Full Course from fast.ai and Jeremy Howard
 1:34:37
1:34:37
Lesson 4: Practical Deep Learning for Coders 2022
 1:42:55
1:42:55
Lesson 6: Practical Deep Learning for Coders 2022
 0:34:38
0:34:38
Introduction to Python Programming | AIML End-to-End Session 12
 0:05:52
0:05:52
Deep Learning | What is Deep Learning? | Deep Learning Tutorial For Beginners | 2023 | Simplilearn
 2:18:39
2:18:39
Intro to Deep Learning 2018 - Lesson 5
 0:05:12
0:05:12
05: Lesson 5: Backprop; Neural Nets from scratch | fast.ai 2019 & Things Jeremy Howard says to d...
 1:46:43
1:46:43
Lesson 7: Practical Deep Learning for Coders 2022
 1:25:17
1:25:17
TWiML x Fast.ai Deep Learning Part 1 Review Study Group Winter 2019 - Lesson 5
 0:04:30
0:04:30
5 tips to improve your critical thinking - Samantha Agoos
 0:04:59
0:04:59
Quantum Computing In 5 Minutes | Quantum Computing Explained | Quantum Computer | Simplilearn
 0:10:49
0:10:49
Lesson 5 - Python Programming (Automate the Boring Stuff with Python)
 0:00:16
0:00:16
Lung inflation in Science Lesson #science #teacher #biology
 2:15:16
2:15:16
Lesson 9: Deep Learning Foundations to Stable Diffusion
 2:03:06
2:03:06
Lesson 6: Practical Deep Learning for Coders
 1:36:55
1:36:55
Lesson 8 - Practical Deep Learning for Coders 2022
 1:16:42
1:16:42
Lesson 2: Practical Deep Learning for Coders 2022
 2:00:35
2:00:35
Lesson 7: Practical Deep Learning for Coders
 1:30:25
1:30:25
Lesson 3: Practical Deep Learning for Coders 2022
Комментарии