filmov
tv
Semi-structured RAG - LangChain using Mistral 7B , Qdrant FastEmbed on pdf text with tabular data

Показать описание
Many documents contain a mixture of content types, including text and tables.
Semi-structured data can be challenging for conventional RAG for at least two reasons:
• Text splitting may break up tables, corrupting the data in retrieval
• Embedding tables may pose challenges for semantic similarity search
This video shows how to perform RAG on documents with semi-structured data:
• We will use Unstructured to parse both text and tables from documents (PDFs).
• We will use the multi-vector retriever to store raw tables, text along with table summaries better suited for retrieval.
• We will use LCEL to implement the chains used.
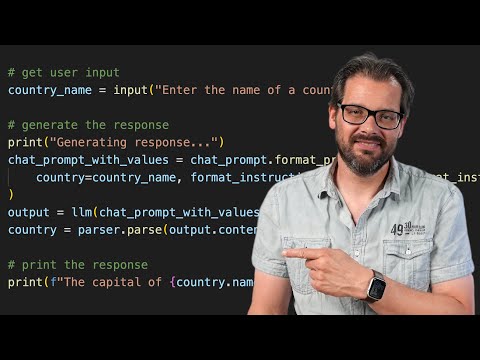
We will use Mistral 7B Instruct as our LLM and use Qdrant FastEmbed for our embedding
Colab notebook:
If you like such content please subscribe to the channel here:
 0:16:10
0:16:10
Semi-structured RAG with LangChain and OpenAI GPT-4 RAG on tabular data , semi structured documents
 0:17:54
0:17:54
Semi-structured RAG - LangChain using Mistral 7B , Qdrant FastEmbed on pdf text with tabular data
 0:21:29
0:21:29
Benchmarking Methods for Semi-Structured RAG
 0:16:06
0:16:06
Multi-Vector Retriever for RAG on Tables + Texts Using LANGCHAIN & UNSTRUCTURED
 0:06:35
0:06:35
RAG from scratch: Part 12 (Multi-Representation Indexing)
 0:22:03
0:22:03
Multi-modal RAG With LANGCHAIN 🦜🔗 & GPT-4V
 0:13:08
0:13:08
Multimodal RAG with GPT-4-Vision and LangChain | Retrieval with Images, Tables and Text
 0:21:08
0:21:08
RAG for long context LLMs
 0:46:30
0:46:30
Fine-Tuning Enterprise RAG Knowledge Bases with Label Studio, ChatGPT, and Ragas
 0:41:28
0:41:28
Realtime Multimodal RAG Usecase Part 1 | Extract Image,Table,Text from Documents #rag #multimodal
 0:19:48
0:19:48
5-Langchain Series-Advanced RAG Q&A Chatbot With Chain And Retrievers Using Langchain
 0:48:55
0:48:55
Building a Multimodal RAG App for Medical Applications
 0:40:59
0:40:59
ADVANCED Python AI Agent Tutorial - Using RAG
 0:15:39
0:15:39
Extract Tables + Texts from .htm pages for RAG Using LLAMA-INDEX & UNSTRUCTURED
 0:18:35
0:18:35
Building Production-Ready RAG Applications: Jerry Liu
 0:30:05
0:30:05
Loading PDF Data Into Langchain : To Use Or Not To Use Unstructured Library
 1:05:30
1:05:30
LangChain Crash Course for Beginners
 0:38:33
0:38:33
LangChain v/s Llama-Index | Detailed Differences | Which one you should use?
 0:18:41
0:18:41
OpenAI Embeddings and Vector Databases Crash Course
 0:14:50
0:14:50
Advanced RAG 02 - Parent Document Retriever
 0:29:58
0:29:58
Chunk large complex PDFs to summarize using LLM
 0:08:41
0:08:41
Advanced RAG with Knowledge Graphs (Neo4J demo)
 0:27:54
0:27:54
Building adaptive RAG from scratch with Command-R
 0:17:42
0:17:42
LangChain is AMAZING | Quick Python Tutorial
Комментарии