filmov
tv
Multi-Vector Retriever for RAG on Tables + Texts Using LANGCHAIN & UNSTRUCTURED

Показать описание
In this video, I will show you how to chat with pdf which contains text as well as tables. We will be using langchain, openai, ChromaDB and Unstructured.
Happy Learning 😎
👉🏼 Links:
------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------
🔗 🎥 Other videos you might find helpful:
------------------------------------------------------------------------------------------
🤝 Connect with me:
#langchian #llm #rag #semistructuredrag #datasciencebasics
Happy Learning 😎
👉🏼 Links:
------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------
🔗 🎥 Other videos you might find helpful:
------------------------------------------------------------------------------------------
🤝 Connect with me:
#langchian #llm #rag #semistructuredrag #datasciencebasics
 0:16:06
0:16:06
Multi-Vector Retriever for RAG on Tables + Texts Using LANGCHAIN & UNSTRUCTURED
 0:18:46
0:18:46
LangChain Multi-Query Retriever for RAG
 0:12:18
0:12:18
Add Chunking to MultiVector for Chatting With Your Data
 0:06:35
0:06:35
RAG from scratch: Part 12 (Multi-Representation Indexing)
 0:13:08
0:13:08
Multimodal RAG with GPT-4-Vision and LangChain | Retrieval with Images, Tables and Text
 0:24:57
0:24:57
LangChain - Advanced RAG Techniques for better Retrieval Performance
 0:11:50
0:11:50
LangChain Retrieval QA Over Multiple Files with ChromaDB
 0:21:44
0:21:44
Realtime Multimodal RAG Usecase Part 3 | MultiVectorRetriever with Langchain | RAG Application #rag
 1:01:29
1:01:29
Create Retrieval-Augmented Generation RAG application in Python From Scratch Ollama Llama LangChain
 0:22:03
0:22:03
Multi-modal RAG With LANGCHAIN 🦜🔗 & GPT-4V
 0:09:16
0:09:16
Better RAG with MultiIndexRetriever : Retrieve full documents
 0:24:36
0:24:36
6-Building Advanced RAG Q&A Project With Multiple Data Sources With Langchain
 0:12:02
0:12:02
Advanced RAG 01 - Self Querying Retrieval
 2:33:11
2:33:11
Learn RAG From Scratch – Python AI Tutorial from a LangChain Engineer
 0:18:35
0:18:35
Building Production-Ready RAG Applications: Jerry Liu
 0:42:35
0:42:35
Hybrid Search RAG With Langchain And Pinecone Vector DB
 0:06:36
0:06:36
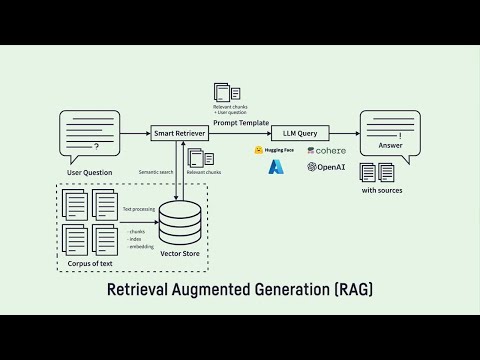
What is Retrieval-Augmented Generation (RAG)?
 0:34:22
0:34:22
How to build Multimodal Retrieval-Augmented Generation (RAG) with Gemini
 0:27:21
0:27:21
End to end RAG LLM App Using Llamaindex and OpenAI- Indexing and Querying Multiple pdf's
 0:05:14
0:05:14
Using Dataiku for Retrieval Augmented Generation (RAG)
 1:01:12
1:01:12
Building Multi-Modal Search with Vector Databases
 0:06:47
0:06:47
Advanced RAG 03 - Hybrid Search BM25 & Ensembles
 0:00:42
0:00:42
😲 Building Advanced RAG systems #ai
 0:16:10
0:16:10
Semi-structured RAG with LangChain and OpenAI GPT-4 RAG on tabular data , semi structured documents
Комментарии