filmov
tv
Spark Internals and Architecture in Azure Databricks

Показать описание
Spark is an open source distributed computing engine. We use it for processing and analyzing a large amount of data. Likewise, hadoop mapreduce, it also works to distribute data across the cluster. It helps to process data in parallel. Spark uses master/slave architecture, one master node, and many slave worker nodes.
0:00 - Overview
0:34 - Introduction
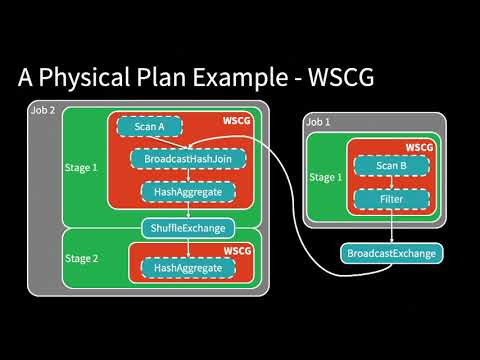
1:27 - Architecture of Spark
357 - Run spark
5:58 - Spark session
6:59 - Run queries
11:05 - Evolution of spark
12:15 - Summary
This is one of my lecture from the course published in Infrasity, if you are looking for Databricks Introductory course, you may purchase the course:
▬▬▬▬▬▬ Other Course link: 🔗▬▬▬▬▬▬
Azure Devops :
Github Actions:
Vault:
▬▬▬▬▬▬ About Infrasity 🔗▬▬▬▬▬▬
Single platform for all the devops courses - We help devops enthusiasts discover courses which will help them learn infrastructure and apply them on real environment 🚀
📌 Follow us on Social and be a part of an amazing tech community📌
👉 Check out student success stories, expert opinions, and live classes
🔔 Hit that bell icon to get notified of all our new videos 🔔
If you liked this video, please don't forget to like and comment. Never miss out on our exclusive videos to help boost your coding career! follow infrasity now for more updates !
▬▬▬▬▬▬ Github Repo's 🔗▬▬▬▬▬▬
🔵 Why should you opt for an Azure data factory course ?
It allows organizations to create data-driven workflows in the cloud for orchestrating and automating data movement and for data transformation. By using leveraging Azure Data Factory, the casino can create and schedule pipelines, or data-driven workflows, that can ingest data from different data stores.
0:00 - Overview
0:34 - Introduction
1:27 - Architecture of Spark
357 - Run spark
5:58 - Spark session
6:59 - Run queries
11:05 - Evolution of spark
12:15 - Summary
This is one of my lecture from the course published in Infrasity, if you are looking for Databricks Introductory course, you may purchase the course:
▬▬▬▬▬▬ Other Course link: 🔗▬▬▬▬▬▬
Azure Devops :
Github Actions:
Vault:
▬▬▬▬▬▬ About Infrasity 🔗▬▬▬▬▬▬
Single platform for all the devops courses - We help devops enthusiasts discover courses which will help them learn infrastructure and apply them on real environment 🚀
📌 Follow us on Social and be a part of an amazing tech community📌
👉 Check out student success stories, expert opinions, and live classes
🔔 Hit that bell icon to get notified of all our new videos 🔔
If you liked this video, please don't forget to like and comment. Never miss out on our exclusive videos to help boost your coding career! follow infrasity now for more updates !
▬▬▬▬▬▬ Github Repo's 🔗▬▬▬▬▬▬
🔵 Why should you opt for an Azure data factory course ?
It allows organizations to create data-driven workflows in the cloud for orchestrating and automating data movement and for data transformation. By using leveraging Azure Data Factory, the casino can create and schedule pipelines, or data-driven workflows, that can ingest data from different data stores.
 0:41:34
0:41:34
 0:09:40
0:09:40
 0:13:05
0:13:05
 0:05:58
0:05:58
 0:21:17
0:21:17
 0:04:11
0:04:11
 0:14:28
0:14:28
 0:10:47
0:10:47
 0:55:26
0:55:26
 0:08:32
0:08:32
 5:58:31
5:58:31
 0:24:07
0:24:07
 0:06:51
0:06:51
 0:12:48
0:12:48
 0:21:03
0:21:03
 0:09:15
0:09:15
 0:54:53
0:54:53
 0:15:04
0:15:04
 0:08:03
0:08:03
 0:44:03
0:44:03
 0:03:00
0:03:00
 0:09:01
0:09:01
 0:21:14
0:21:14
 0:39:32
0:39:32