filmov
tv
How Do Spark Window Functions Work? A Practical Guide to PySpark Window Functions ❌PySpark Tutorial

Показать описание
Microsoft Azure Certified:
Databricks Certified:
---
---
COURSERA SPECIALIZATIONS:
COURSES:
LEARN PYTHON:
LEARN SQL:
LEARN STATISTICS:
LEARN MACHINE LEARNING:
---
For business enquiries please connect with me on LinkedIn or book a call:
Disclaimer: I may earn a commission if you decide to use the links above. Thank you for supporting the channel!
#DecisionForest
 0:10:49
0:10:49
How Do Spark Window Functions Work? A Practical Guide to PySpark Window Functions ❌PySpark Tutorial...
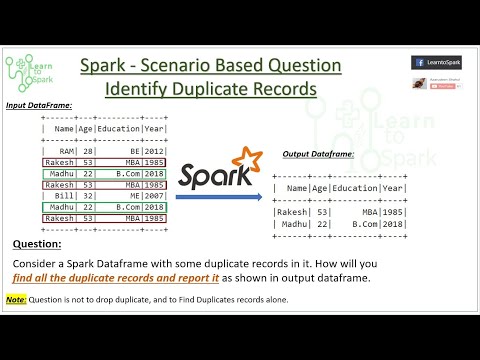 0:06:56
0:06:56
Spark Scenario Based Question | Window - Ranking Function in Spark | Using PySpark | LearntoSpark
 0:10:11
0:10:11
How to use Windowing Functions in Apache Spark | Window Functions | OVER | PARTITION BY | ORDER BY
 0:18:23
0:18:23
PySpark Tutorial 16: PySpark Window Function | PySpark with Python
![[Live Demo] Spark](https://i.ytimg.com/vi/WQgHKPCwr8A/hqdefault.jpg) 0:12:10
0:12:10
[Live Demo] Spark Window Functions | Spark Aggregate Functions | Spark Structured Streaming Tutorial
 0:10:34
0:10:34
Spark Window Function | Spark Tutorial | Interview Question
 0:25:04
0:25:04
Spark Window Functions: An Easy and Comprehensive Tutorial.
 0:12:27
0:12:27
108. Databricks | Pyspark| Window Function: First and Last
 1:06:55
1:06:55
HADOOP + PYSPARK + PYTHON + LINUX tutorial || by Mr. N. Vijay Sunder Sagar On 21-07-2024 @8PM IST
 0:02:44
0:02:44
How to use Percent_Rank() window function in spark with example
 0:12:22
0:12:22
Apache Spark Use Case | Spark Scenario on Join and Window Function | Using PySpark
 0:05:27
0:05:27
Spark SQL - Windowing Functions - Overview
 0:06:32
0:06:32
Spark with Scala Course - #12 Window Functions
 0:13:26
0:13:26
54. row_number(), rank(), dense_rank() functions in PySpark | #pyspark #spark #azuresynapse #azure
 0:03:19
0:03:19
How to use ntile() window function in spark with example
 0:57:43
0:57:43
Apache Spark - Window Functions, SparkUI- what, how to look all info , RangePartitioner
 0:09:50
0:09:50
What are windowing functions in stream analytics
 0:29:46
0:29:46
window function in pyspark | rank and dense_rank | Lec-15
 0:04:21
0:04:21
Spark Window Functions part-1 | Window functions | spark | PySpark Tutorial | Pyspark course |
 0:12:36
0:12:36
Spark SQL for Data Engineering 24 : Spark Sql window aggregate functions #sum #sparksql #sqlwindow
 0:24:25
0:24:25
Master Databricks and Apache Spark Step by Step: Lesson 16 - Using SQL Window Functions
 0:17:51
0:17:51
PySpark Window Functions
 0:03:02
0:03:02
How to use Row_Number() window function in spark with example
 0:04:56
0:04:56
Windowing Functions in Spark SQL Part 2 | First Value & Last Value Functions | Window Functions
Комментарии