filmov
tv
Best Optimization Techniques for Loading Large CSV Data to ORC Format in Spark SQL

Показать описание
Disclaimer/Disclosure: Some of the content was synthetically produced using various Generative AI (artificial intelligence) tools; so, there may be inaccuracies or misleading information present in the video. Please consider this before relying on the content to make any decisions or take any actions etc. If you still have any concerns, please feel free to write them in a comment. Thank you.
---
Summary: Discover effective methods for optimizing the loading of large CSV files into ORC format using Spark SQL. Enhance performance and efficiency in your data processing pipelines.
---
Best Optimization Techniques for Loading Large CSV Data to ORC Format in Spark SQL
Handling large CSV files in a big data environment can be challenging. Apache Spark SQL provides a powerful framework to manage massive datasets, but optimization is crucial for performance and efficiency. This guide delves into techniques to optimize the process of loading large CSV files into ORC (Optimized Row Columnar) format using Spark SQL.
Why Choose ORC Format?
Before diving into the optimization techniques, it’s important to understand why we convert CSV data to ORC format:
Compression: ORC format offers efficient compression which reduces the storage footprint.
Splittable: ORC files improve the read efficiency and support splitting, which is not possible with traditional CSV files.
Schema Evolution: ORC provides extensive support for schema evolution, easing data management over time.
Performance: ORC files allow for faster read and write operations thanks to their columnar storage design.
Optimization Techniques
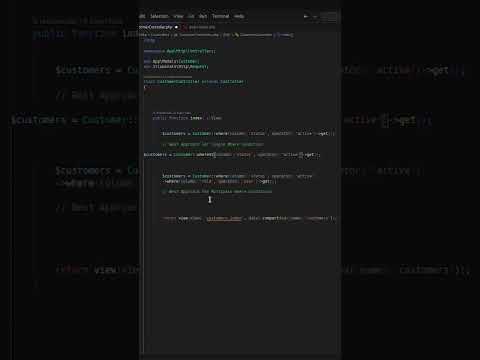
Efficient Reading of CSV Files
Reading large CSV files directly without optimizations can cause significant overhead. To enhance the reading process:
Use Infer Schema: Turn off inferSchema if you have a predefined schema. Inferring schemas on large datasets can be time-consuming.
[[See Video to Reveal this Text or Code Snippet]]
Set Appropriate Options: Use options like delimiter, quote, and escape based on your CSV structure to avoid unnecessary parsing errors.
Distributed Processing
Spark benefits from its distributed processing capabilities. Ensuring data is evenly distributed across all nodes can significantly increase performance:
Repartition DataFrame: Repartition your DataFrame based on the size of your dataset or the number of cores.
[[See Video to Reveal this Text or Code Snippet]]
Utilize Caching
Caching intermediate results can save time if the same data is used multiple times:
Cache DataFrames: Before performing multiple operations on a DataFrame, cache it to keep it in memory.
[[See Video to Reveal this Text or Code Snippet]]
4.Write DataFrame to ORC
When writing the DataFrame to ORC format, leverage partitioning and bucketing features:
Partition By: Partition the data based on a logical column like date or category to improve read performance in later queries.
[[See Video to Reveal this Text or Code Snippet]]
Bucketing: Create multiple buckets within each partition for finer-grained organization.
[[See Video to Reveal this Text or Code Snippet]]
Conclusion
Optimizing the process of loading large CSV files into ORC format using Spark SQL is vital to make full use of Spark's distributed processing capabilities. By effectively managing schema inference, repartitioning data, caching results, and utilizing partitioning and bucketing, one can achieve significant performance improvements.
Applying these optimization techniques will not only enhance the efficiency of your data processing pipelines but also ensure that you can handle substantial datasets with ease. So, the next time you're faced with the task of handling large CSV files, these strategies will help you tackle the challenge efficiently.
---
Summary: Discover effective methods for optimizing the loading of large CSV files into ORC format using Spark SQL. Enhance performance and efficiency in your data processing pipelines.
---
Best Optimization Techniques for Loading Large CSV Data to ORC Format in Spark SQL
Handling large CSV files in a big data environment can be challenging. Apache Spark SQL provides a powerful framework to manage massive datasets, but optimization is crucial for performance and efficiency. This guide delves into techniques to optimize the process of loading large CSV files into ORC (Optimized Row Columnar) format using Spark SQL.
Why Choose ORC Format?
Before diving into the optimization techniques, it’s important to understand why we convert CSV data to ORC format:
Compression: ORC format offers efficient compression which reduces the storage footprint.
Splittable: ORC files improve the read efficiency and support splitting, which is not possible with traditional CSV files.
Schema Evolution: ORC provides extensive support for schema evolution, easing data management over time.
Performance: ORC files allow for faster read and write operations thanks to their columnar storage design.
Optimization Techniques
Efficient Reading of CSV Files
Reading large CSV files directly without optimizations can cause significant overhead. To enhance the reading process:
Use Infer Schema: Turn off inferSchema if you have a predefined schema. Inferring schemas on large datasets can be time-consuming.
[[See Video to Reveal this Text or Code Snippet]]
Set Appropriate Options: Use options like delimiter, quote, and escape based on your CSV structure to avoid unnecessary parsing errors.
Distributed Processing
Spark benefits from its distributed processing capabilities. Ensuring data is evenly distributed across all nodes can significantly increase performance:
Repartition DataFrame: Repartition your DataFrame based on the size of your dataset or the number of cores.
[[See Video to Reveal this Text or Code Snippet]]
Utilize Caching
Caching intermediate results can save time if the same data is used multiple times:
Cache DataFrames: Before performing multiple operations on a DataFrame, cache it to keep it in memory.
[[See Video to Reveal this Text or Code Snippet]]
4.Write DataFrame to ORC
When writing the DataFrame to ORC format, leverage partitioning and bucketing features:
Partition By: Partition the data based on a logical column like date or category to improve read performance in later queries.
[[See Video to Reveal this Text or Code Snippet]]
Bucketing: Create multiple buckets within each partition for finer-grained organization.
[[See Video to Reveal this Text or Code Snippet]]
Conclusion
Optimizing the process of loading large CSV files into ORC format using Spark SQL is vital to make full use of Spark's distributed processing capabilities. By effectively managing schema inference, repartitioning data, caching results, and utilizing partitioning and bucketing, one can achieve significant performance improvements.
Applying these optimization techniques will not only enhance the efficiency of your data processing pipelines but also ensure that you can handle substantial datasets with ease. So, the next time you're faced with the task of handling large CSV files, these strategies will help you tackle the challenge efficiently.
 0:06:43
0:06:43
 0:05:11
0:05:11
 0:11:23
0:11:23
 0:05:23
0:05:23
 0:00:15
0:00:15
 0:11:25
0:11:25
 0:00:27
0:00:27
 0:00:09
0:00:09
 0:00:58
0:00:58
 0:00:52
0:00:52
 0:00:23
0:00:23
 0:01:44
0:01:44
 0:04:45
0:04:45
 0:08:28
0:08:28
 1:10:32
1:10:32
 0:00:29
0:00:29
 0:04:08
0:04:08
 0:16:18
0:16:18
 0:16:10
0:16:10
 0:14:06
0:14:06
 0:09:16
0:09:16
 0:00:32
0:00:32
 0:00:15
0:00:15
 0:00:21
0:00:21