filmov
tv
How to Save HTML String to PDF Using Python

Показать описание
Disclaimer/Disclosure: Some of the content was synthetically produced using various Generative AI (artificial intelligence) tools; so, there may be inaccuracies or misleading information present in the video. Please consider this before relying on the content to make any decisions or take any actions etc. If you still have any concerns, please feel free to write them in a comment. Thank you.
---
Summary: Learn how to convert an HTML string to a PDF file programmatically in Python using libraries such as WeasyPrint or pdfkit. Explore step-by-step instructions to efficiently generate PDFs from HTML content.
---
When working with Python, you may encounter situations where you need to convert HTML content, either stored as a string or generated dynamically, into a PDF file. This process can be useful for generating reports, exporting web pages, or creating printable documents. Thankfully, Python offers several libraries that simplify this task. In this guide, we'll explore how to save an HTML string to a PDF using two popular libraries: WeasyPrint and pdfkit.
Using WeasyPrint
WeasyPrint is a powerful library for rendering HTML and CSS content into PDF files. Here's how you can use it to convert an HTML string to a PDF:
[[See Video to Reveal this Text or Code Snippet]]
In the code above, we first import the HTML class from WeasyPrint. Then, we define our HTML content as a string. Finally, we use the write_pdf method to convert the HTML string to a PDF file and save it with the specified filename.
Using pdfkit
pdfkit is another popular library that provides a Python wrapper for the wkhtmltopdf tool, allowing you to convert HTML to PDF using the WebKit rendering engine. Here's how you can achieve the same task using pdfkit:
[[See Video to Reveal this Text or Code Snippet]]
In this code snippet, we import the pdfkit module and use the from_string function to convert the HTML string to a PDF file. Similar to WeasyPrint, the output PDF file is specified by providing the desired filename.
Conclusion
Converting HTML content to PDF files in Python is a straightforward process thanks to libraries like WeasyPrint and pdfkit. Whether you prefer the simplicity of pdfkit or the flexibility of WeasyPrint, both options allow you to generate high-quality PDFs from HTML strings efficiently.
By following the examples provided in this guide, you can seamlessly integrate HTML to PDF conversion functionality into your Python applications, enabling you to produce professional-looking documents with ease.
---
Summary: Learn how to convert an HTML string to a PDF file programmatically in Python using libraries such as WeasyPrint or pdfkit. Explore step-by-step instructions to efficiently generate PDFs from HTML content.
---
When working with Python, you may encounter situations where you need to convert HTML content, either stored as a string or generated dynamically, into a PDF file. This process can be useful for generating reports, exporting web pages, or creating printable documents. Thankfully, Python offers several libraries that simplify this task. In this guide, we'll explore how to save an HTML string to a PDF using two popular libraries: WeasyPrint and pdfkit.
Using WeasyPrint
WeasyPrint is a powerful library for rendering HTML and CSS content into PDF files. Here's how you can use it to convert an HTML string to a PDF:
[[See Video to Reveal this Text or Code Snippet]]
In the code above, we first import the HTML class from WeasyPrint. Then, we define our HTML content as a string. Finally, we use the write_pdf method to convert the HTML string to a PDF file and save it with the specified filename.
Using pdfkit
pdfkit is another popular library that provides a Python wrapper for the wkhtmltopdf tool, allowing you to convert HTML to PDF using the WebKit rendering engine. Here's how you can achieve the same task using pdfkit:
[[See Video to Reveal this Text or Code Snippet]]
In this code snippet, we import the pdfkit module and use the from_string function to convert the HTML string to a PDF file. Similar to WeasyPrint, the output PDF file is specified by providing the desired filename.
Conclusion
Converting HTML content to PDF files in Python is a straightforward process thanks to libraries like WeasyPrint and pdfkit. Whether you prefer the simplicity of pdfkit or the flexibility of WeasyPrint, both options allow you to generate high-quality PDFs from HTML strings efficiently.
By following the examples provided in this guide, you can seamlessly integrate HTML to PDF conversion functionality into your Python applications, enabling you to produce professional-looking documents with ease.
 0:01:06
0:01:06
 0:01:12
0:01:12
 0:01:19
0:01:19
 0:02:18
0:02:18
 0:02:31
0:02:31
 0:00:24
0:00:24
 0:04:27
0:04:27
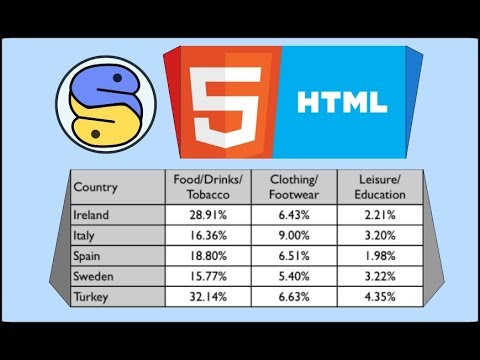 0:01:54
0:01:54
 0:01:28
0:01:28
 0:01:40
0:01:40
 0:02:35
0:02:35
 0:01:17
0:01:17
 0:08:39
0:08:39
 0:02:23
0:02:23
 0:00:30
0:00:30
 0:20:18
0:20:18
 0:00:19
0:00:19
 0:00:16
0:00:16
 0:03:16
0:03:16
 0:00:15
0:00:15
 0:24:38
0:24:38
 0:05:45
0:05:45
 0:00:30
0:00:30
 0:01:07
0:01:07