filmov
tv
Data Ingestion Fast & Slow: How to Improve Data Availability & Data Quality w/ Right-Time Processing

Показать описание
Gartner estimates the average business will lose ten million dollars annually due to data quality problems, and every week we hear another cautionary tale of an AI model gone awry. Technology that unifies batch and streaming has massive but overlooked implications for our ability to trust our data.
In this session, we'll demonstrate how architectures that can move between batch and incremental processing without changing the storage and API allow us to solve common data trust problems, such as stale data, as well as production ML risks, such as concept drift. We call this capability “Right-Time Processing.” This session is for data architects and practitioners. You don't need to be an ML or ETL expert to attend, but an interest in data architecture is critical.
Talk by: Dillon Bostwick
Here’s more to explore:
In this session, we'll demonstrate how architectures that can move between batch and incremental processing without changing the storage and API allow us to solve common data trust problems, such as stale data, as well as production ML risks, such as concept drift. We call this capability “Right-Time Processing.” This session is for data architects and practitioners. You don't need to be an ML or ETL expert to attend, but an interest in data architecture is critical.
Talk by: Dillon Bostwick
Here’s more to explore:
 0:34:33
0:34:33
Data Ingestion Fast & Slow: How to Improve Data Availability & Data Quality w/ Right-Time Pr...
 0:08:12
0:08:12
5 Secrets for making PostgreSQL run BLAZING FAST. How to improve database performance.
 0:05:25
0:05:25
What is Data Pipeline? | Why Is It So Popular?
 0:38:19
0:38:19
Hassle-Free Data Ingestion into the Lakehouse
 0:59:25
0:59:25
Accelerating Data Ingestion with Databricks Autoloader
 0:16:34
0:16:34
Scale Your Data Ingestion With an Ingestion Framework
 0:05:57
0:05:57
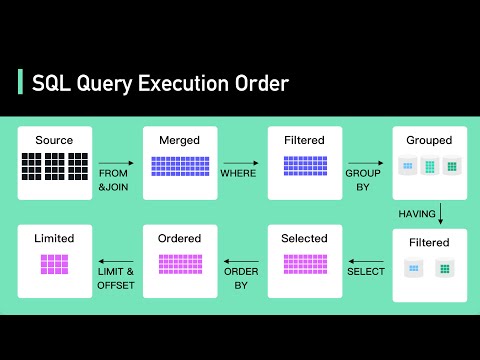
Secret To Optimizing SQL Queries - Understand The SQL Execution Order
 0:04:08
0:04:08
SQL indexing best practices | How to make your database FASTER!
 0:03:09
0:03:09
SingleStore Snackables: Streaming Data Ingestion
 0:05:22
0:05:22
Database vs Data Warehouse vs Data Lake | What is the Difference?
 1:20:09
1:20:09
Data Ingestion From APIs to Warehouses - Adrian Brudaru
 0:06:05
0:06:05
Data Ingestion 101 | Explained in 5 Minutes
 1:05:52
1:05:52
Data Ingestion and Replication for Analytics & AI
 0:00:41
0:00:41
Is slow data holding you back?
![[PingCAP Meetup] Real-time](https://i.ytimg.com/vi/iwEpKYA4AHE/hqdefault.jpg) 1:01:31
1:01:31
[PingCAP Meetup] Real-time Large Scale Data Ingestion and Analytical Service
 0:21:01
0:21:01
Data Ingestion Performance Optimizations | Azure SQL and ADF Event | Data Exposed Special
 0:02:27
0:02:27
MongoDB in 100 Seconds
 0:33:59
0:33:59
AWS re:Invent 2017: Data Ingestion at Seismic Scale: Best practices for processing p (EUT302)
 1:02:05
1:02:05
Data Streams Decoded Optimizing Data Ingestion with Spark in Microsoft Fabric
 0:20:31
0:20:31
Real-Time Data Ingestion at DTCC with Solace and Snowpipe
 0:12:11
0:12:11
Benjamin Kettner - From zero to data ingestion: building an IoT Pipeline in 10 minutes
 0:37:21
0:37:21
SingleStore Ecosystem: A Primer on Data Ingestion | SingleStore Webinars
 0:04:31
0:04:31
Dataflow a remedy slow data sources in Power BI
 0:40:59
0:40:59
Data Ingestion
Комментарии