filmov
tv
Read Tables from HTML page using Python Pandas - P1.5

Показать описание
Read Tables from HTML page using Python Pandas - P1.5
Topic to be covered - Read table from HTML Page
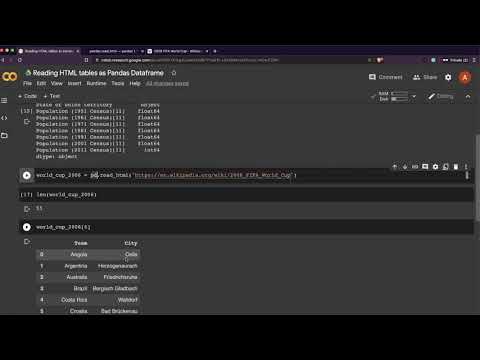
io : str or file-like
A URL, a file-like object, or a raw string containing HTML. Note that lxml only accepts the http, ftp and file url protocols. If you have a URL that starts with 'https' you might try removing the 's'.
match : str or compiled regular expression, optional
The set of tables containing text matching this regex or string will be returned. Unless the HTML is extremely simple you will probably need to pass a non-empty string here. Defaults to ‘.+’ (match any non-empty string). The default value will return all tables contained on a page. This value is converted to a regular expression so that there is consistent behavior between Beautiful Soup and
lxml.
flavor : str or None, container of strings
The parsing engine to use. ‘bs4’ and ‘html5lib’ are synonymous with each other, they are both there for backwards compatibility. The default of None tries to use lxml to parse and if that fails it falls back on bs4 + html5lib.
header : int or list-like or None, optional
The row (or list of rows for a MultiIndex) to use to make the columns headers.
index_col : int or list-like or None, optional
The column (or list of columns) to use to create the index.
skiprows : int or list-like or slice or None, optional
0-based. Number of rows to skip after parsing the column integer. If a sequence of integers or a slice is given, will skip the rows indexed by that sequence. Note that a single element sequence means ‘skip the nth row’ whereas an integer means ‘skip n rows’.
attrs : dict or None, optional
This is a dictionary of attributes that you can pass to use to identify the table in the HTML. These are not checked for validity before being passed to lxml or Beautiful Soup. However, these attributes must be valid HTML table attributes to work correctly. For example,
Code Starts Here
==============
import pandas as pd
All Playlist of this youtube channel
============================
1. Data Preprocessing in Machine Learning
2. Confusion Matrix in Machine Learning, ML, AI
3. Anaconda, Python Installation, Spyder, Jupyter Notebook, PyCharm, Graphviz
4. Cross Validation, Sampling, train test split in Machine Learning
5. Drop and Delete Operations in Python Pandas
6. Matrices and Vectors with python
7. Detect Outliers in Machine Learning
8. TimeSeries preprocessing in Machine Learning
9. Handling Missing Values in Machine Learning
10. Dummy Encoding Encoding in Machine Learning
11. Data Visualisation with Python, Seaborn, Matplotlib
12. Feature Scaling in Machine Learning
13. Python 3 basics for Beginner
14. Statistics with Python
15. Sklearn Scikit Learn Machine Learning
16. Python Pandas Dataframe Operations
Topic to be covered - Read table from HTML Page
io : str or file-like
A URL, a file-like object, or a raw string containing HTML. Note that lxml only accepts the http, ftp and file url protocols. If you have a URL that starts with 'https' you might try removing the 's'.
match : str or compiled regular expression, optional
The set of tables containing text matching this regex or string will be returned. Unless the HTML is extremely simple you will probably need to pass a non-empty string here. Defaults to ‘.+’ (match any non-empty string). The default value will return all tables contained on a page. This value is converted to a regular expression so that there is consistent behavior between Beautiful Soup and
lxml.
flavor : str or None, container of strings
The parsing engine to use. ‘bs4’ and ‘html5lib’ are synonymous with each other, they are both there for backwards compatibility. The default of None tries to use lxml to parse and if that fails it falls back on bs4 + html5lib.
header : int or list-like or None, optional
The row (or list of rows for a MultiIndex) to use to make the columns headers.
index_col : int or list-like or None, optional
The column (or list of columns) to use to create the index.
skiprows : int or list-like or slice or None, optional
0-based. Number of rows to skip after parsing the column integer. If a sequence of integers or a slice is given, will skip the rows indexed by that sequence. Note that a single element sequence means ‘skip the nth row’ whereas an integer means ‘skip n rows’.
attrs : dict or None, optional
This is a dictionary of attributes that you can pass to use to identify the table in the HTML. These are not checked for validity before being passed to lxml or Beautiful Soup. However, these attributes must be valid HTML table attributes to work correctly. For example,
Code Starts Here
==============
import pandas as pd
All Playlist of this youtube channel
============================
1. Data Preprocessing in Machine Learning
2. Confusion Matrix in Machine Learning, ML, AI
3. Anaconda, Python Installation, Spyder, Jupyter Notebook, PyCharm, Graphviz
4. Cross Validation, Sampling, train test split in Machine Learning
5. Drop and Delete Operations in Python Pandas
6. Matrices and Vectors with python
7. Detect Outliers in Machine Learning
8. TimeSeries preprocessing in Machine Learning
9. Handling Missing Values in Machine Learning
10. Dummy Encoding Encoding in Machine Learning
11. Data Visualisation with Python, Seaborn, Matplotlib
12. Feature Scaling in Machine Learning
13. Python 3 basics for Beginner
14. Statistics with Python
15. Sklearn Scikit Learn Machine Learning
16. Python Pandas Dataframe Operations
 0:11:36
0:11:36
 0:04:49
0:04:49
 0:06:46
0:06:46
 0:03:18
0:03:18
 0:11:16
0:11:16
 0:06:45
0:06:45
 0:09:06
0:09:06
 0:06:30
0:06:30
 0:11:09
0:11:09
 0:08:59
0:08:59
 0:03:57
0:03:57
 0:01:38
0:01:38
 0:03:39
0:03:39
 0:11:23
0:11:23
 0:03:11
0:03:11
 0:05:33
0:05:33
 0:17:55
0:17:55
 0:06:21
0:06:21
 0:20:17
0:20:17
 0:11:40
0:11:40
 0:05:03
0:05:03
 0:02:56
0:02:56
 0:05:19
0:05:19
 0:17:49
0:17:49