filmov
tv
Logistic Regression for Classification | Working with a real-world dataset from Kaggle

Показать описание
🎯 Topics Covered
• Downloading a real-world dataset from Kaggle
• Splitting a dataset into training, validation & test sets
• Imputing and scaling numeric features
• Encoding categorical columns as one-hot vectors
• Training a logistic regression model using Scikit-learn
• Evaluating a model using a validation set and test set
classification/17915
⌚ Time Stamps:
00:00 Introduction
05:16 Problem Statement
25:43 Downloading a real-world dataset from Kaggle
35:35 Exploring data analysis and visualization
47:06 Splitting a dataset into training, validation & test sets
01:03:04 Filling/Imputing missing values in numeric columns
01:21:55 Scaling numeric features to a(0,1) range
01:28:10 Encoding categorical columns as one-hot vectors
01:39:02 Training a logistic regression model using Scikit-learn
01:53:41 Evaluating a model using a validation set and test set
02:19:38 Saving a model to disk and loading it back
02:36:28 Summary and Conclusion
⚡ Free Certification Course
🎤 About the speaker
Aakash N S is the co-founder and CEO of Jovian - a community learning platform for data science & ML. Previously, Aakash has worked as a software engineer (APIs & Data Platforms) at Twitter in Ireland & San Francisco and graduated from the Indian Institute of Technology, Bombay. He’s also an avid blogger, open-source contributor, and online educator.
#GBM #MachineLearning #Python #Certification #Course #Jovian
-
 0:03:48
0:03:48
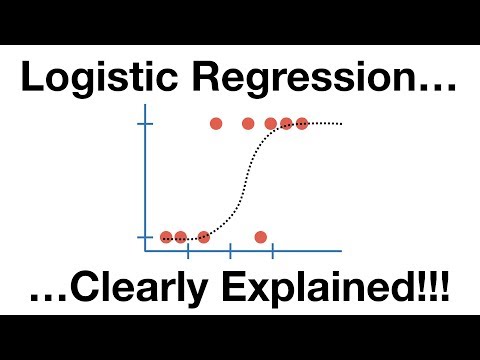
Logistic Regression in 3 Minutes
 0:08:48
0:08:48
StatQuest: Logistic Regression
 0:19:19
0:19:19
Machine Learning Tutorial Python - 8: Logistic Regression (Binary Classification)
 0:12:40
0:12:40
Tutorial 35- Logistic Regression Indepth Intuition- Part 1| Data Science
 0:14:22
0:14:22
Logistic Regression [Simply explained]
 0:07:49
0:07:49
Logistic Regression 2 Classification
 2:40:07
2:40:07
Logistic Regression for Classification | Working with a real-world dataset from Kaggle
 0:10:01
0:10:01
Lec-5: Logistic Regression with Simplest & Easiest Example | Machine Learning
 0:47:11
0:47:11
ML with Python : Zero to Hero | Video 7 | Part 1 | Model Selection | Venkat Reddy AI Classes
 0:04:28
0:04:28
7. Multi class classification using Logistic Regression
 0:06:39
0:06:39
Tutorial 36- Logistic Regression Mutliclass Classification(OneVsRest)- Part 3| Data Science
 0:05:04
0:05:04
Linear Regression vs Logistic Regression - What's The Difference?
 0:05:39
0:05:39
Why is Logistic Called Regression and not Classification | Logistic Regression or Classification
 0:09:14
0:09:14
Logistic Regression - THE MATH YOU SHOULD KNOW!
 0:13:10
0:13:10
Logistic Regression Algorithm in Machine Learning with Solved Numerical Example by Mahesh Huddar
 0:06:37
0:06:37
Logistic Regression Machine Learning Example | Simply Explained
 0:38:17
0:38:17
Logistic Regression | Logistic Regression in Python | Machine Learning Algorithms | Simplilearn
 0:20:27
0:20:27
Linear Regression vs Logistic Regression | Data Science Training | Edureka
 0:05:16
0:05:16
Logistic regression 5.1: Multiclass - One-vs-rest classification
 0:14:04
0:14:04
How to implement Logistic Regression from scratch with Python
 0:18:48
0:18:48
Logistic Regression (Binary Classification) | Machine Learning Tutorial
 0:18:39
0:18:39
Step by Step Tutorial on Logistic Regression in Python | sklearn |Jupyter Notebook
 0:00:55
0:00:55
Logistic regression is a classification algorithm #shorts
 0:11:46
0:11:46
Logistic Regression Explained in Hindi
Комментарии