filmov
tv
CppCon 2019: Conor Hoekstra, “Algorithm Intuition (part 2 of 2)”
Показать описание
—
—
—
Data structure intuition is something that develops naturally for most software developers. In all languages, we rely heavily on standard containers and collections. Need fast insertion/lookup? Hashmap. Need a sorted data structure that stores unique values? Set. Duplicate values? Multiset. And so on.
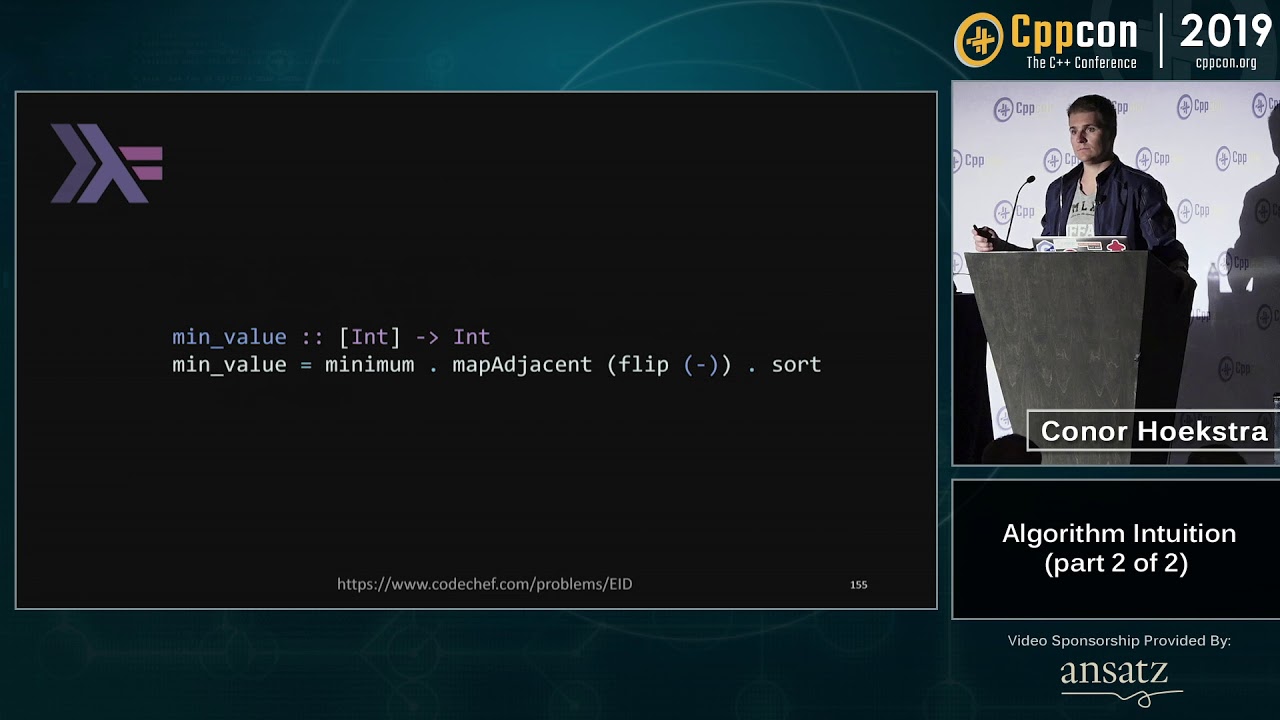
However, most software developers don't develop algorithm intuition quite as easily. Algorithms aren't taught as widely as data structures are, and aren't relied on as heavily. This talk aims to introduce some STL algorithms, show how they are commonly used, and show how by developing intuition about them (+ a little help from lambdas), you can unlock their true potential.
—
Conor Hoekstra
Amazon
Software Development Engineer
San Francisco Bay Area
Conor is extremely passionate about programming languages, algorithms and beautiful code. He spent 5 years in Canada working on a large-scale C++ codebase. In 2018, he moved down to Silicon Valley and has spent the last year working for Amazon using C++, Java, Python, Go, Perl and more. He is in the midst of falling in love with Haskell and functional programming. He also has a YouTube channel where he covers solutions to competitive programming problems and more.
—
*-----*
*-----*
—
—
Data structure intuition is something that develops naturally for most software developers. In all languages, we rely heavily on standard containers and collections. Need fast insertion/lookup? Hashmap. Need a sorted data structure that stores unique values? Set. Duplicate values? Multiset. And so on.
However, most software developers don't develop algorithm intuition quite as easily. Algorithms aren't taught as widely as data structures are, and aren't relied on as heavily. This talk aims to introduce some STL algorithms, show how they are commonly used, and show how by developing intuition about them (+ a little help from lambdas), you can unlock their true potential.
—
Conor Hoekstra
Amazon
Software Development Engineer
San Francisco Bay Area
Conor is extremely passionate about programming languages, algorithms and beautiful code. He spent 5 years in Canada working on a large-scale C++ codebase. In 2018, he moved down to Silicon Valley and has spent the last year working for Amazon using C++, Java, Python, Go, Perl and more. He is in the midst of falling in love with Haskell and functional programming. He also has a YouTube channel where he covers solutions to competitive programming problems and more.
—
*-----*
*-----*
 1:01:16
1:01:16
CppCon 2019: Conor Hoekstra “Algorithm Intuition (part 1 of 2)”
 1:01:27
1:01:27
CppCon 2019: Conor Hoekstra, “Algorithm Intuition (part 2 of 2)”
 1:28:59
1:28:59
C++Now 2019: Conor Hoekstra “Algorithm Intuition”
 0:05:15
0:05:15
23 Ranges: slide & stride - Conor Hoekstra - CppCon 2019
 0:57:03
0:57:03
Better Algorithm Intuition - Conor Hoekstra - code::dive 2019
 0:58:34
0:58:34
Better Algorithm Intuition - Conor Hoekstra @code_report - Meeting C++ 2019
 0:07:33
0:07:33
Consistently Inconsistent - Conor Hoekstra @code_report - Meeting C++ 2019 Secret Lightning Talks
 0:04:47
0:04:47
C++Now 2019: Conor Hoekstra “C++ Algorithms in Haskell and the Haskell Playground”
 1:11:54
1:11:54
Conor Hoekstra — ITM: My least favorite anti-pattern
 1:48:43
1:48:43
Conor Hoekstra : Better Algorithm Intuition
 0:05:15
0:05:15
SICP Cover Demystified - Conor Hoekstra - CppCon 2020
 0:36:10
0:36:10
CppCon 2019: Emery Berger “Mesh: Automatically Compacting Your C++ Application's Memory”
 1:06:27
1:06:27
Structure and Interpretation of Computer Programs: SICP - Conor Hoekstra - CppCon 2020
 1:35:03
1:35:03
The Twin Algorithms - Conor Hoekstra - CppNorth 2022
 0:59:08
0:59:08
CppCon 2019: Peter Bindels & Sy Brand 'Hello World From Scratch'
 0:53:51
0:53:51
itCppCon23 New Algorithms in C++23 (Conor Hoekstra)
 1:00:51
1:00:51
CppCon 2019: Arthur O'Dwyer “Back to Basics: Smart Pointers”
 0:05:21
0:05:21
Algorithm Magic - René Rivera - CppCon 2019
 0:05:08
0:05:08
Conor Hoekstra : Consistently Inconsistent
 0:48:53
0:48:53
From Algorithm to Generic, Parallel Code - Dietmar Kuhl - CppCon 2019
 0:36:59
0:36:59
Thrust and the C++ Standard Algorithms - Conor Hoekstra - GTC 2021
 0:59:22
0:59:22
CppCon 2019: Matthew Butler “If You Can't Open It, You Don't Own It”
 0:52:09
0:52:09
Back to Basics: Lambdas from Scratch - Arthur O'Dwyer - CppCon 2019
 0:52:59
0:52:59
CppCon 2019: David Olsen “Faster Code Through Parallelism on CPUs and GPUs”
Комментарии