filmov
tv
python pandas vs pyspark

Показать описание
title: a comprehensive guide to python pandas vs. pyspark
introduction:
python pandas and pyspark are two powerful tools for data manipulation and analysis, each designed to handle big data tasks efficiently. in this tutorial, we will compare python pandas and pyspark, exploring their features, use cases, and providing code examples to showcase their capabilities.
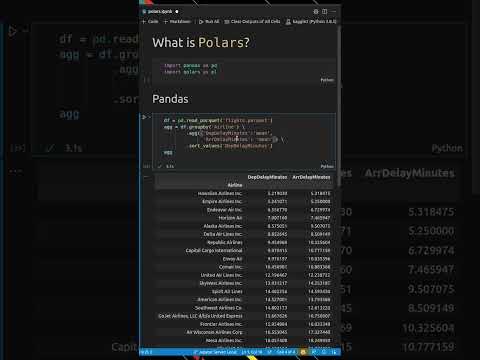
pandas is a widely-used data manipulation library in python, known for its simplicity and ease of use. it is particularly suitable for small to medium-sized datasets that fit into memory.
dataframe: the core data structure in pandas is the dataframe, a two-dimensional, size-mutable, and labeled tabular structure. it can be compared to a spreadsheet or sql table.
data cleaning and transformation: pandas provides a rich set of functions for cleaning and transforming data, including handling missing values, filtering, sorting, and reshaping.
data indexing: pandas allows for efficient indexing, slicing, and subsetting of data, making it easy to work with specific subsets of your dataset.
pyspark, on the other hand, is a distributed computing library for big data processing, built on top of apache spark. it is designed to handle large-scale data processing tasks across a cluster of machines.
resilient distributed datasets (rdds): pyspark operates on rdds, which are fault-tolerant distributed collections of objects. rdds enable parallel processing of data across a cluster.
dataframe and sql support: similar to pandas, pyspark also supports dataframes, providing a high-level api for distributed data manipulation. it also allows querying data using sql.
built-in machine learning libraries: pyspark includes mllib, a scalable machine learning library, making it suitable for machine learning tasks on large datasets.
pandas:
pyspark:
let's explore a simple example to showcase the difference between pandas and pyspark using a hypothetical dataset.
in summary, pandas is well-suited for in-memory data manipulation on sma ...
#python pandas documentation
#python pandas install
#python pandas read csv
#python pandas library
#python pandas dataframe
Related videos on our channel:
python pandas documentation
python pandas install
python pandas read csv
python pandas library
python pandas dataframe
python pandas read excel
python pandas
python pandas rename column
python pandas cheat sheet
python pandas tutorial
python pyspark install
python pyspark
python pyspark resume
python pyspark read csv
python pyspark tutorial
python pyspark example
python pyspark cheat sheet
python pyspark package
introduction:
python pandas and pyspark are two powerful tools for data manipulation and analysis, each designed to handle big data tasks efficiently. in this tutorial, we will compare python pandas and pyspark, exploring their features, use cases, and providing code examples to showcase their capabilities.
pandas is a widely-used data manipulation library in python, known for its simplicity and ease of use. it is particularly suitable for small to medium-sized datasets that fit into memory.
dataframe: the core data structure in pandas is the dataframe, a two-dimensional, size-mutable, and labeled tabular structure. it can be compared to a spreadsheet or sql table.
data cleaning and transformation: pandas provides a rich set of functions for cleaning and transforming data, including handling missing values, filtering, sorting, and reshaping.
data indexing: pandas allows for efficient indexing, slicing, and subsetting of data, making it easy to work with specific subsets of your dataset.
pyspark, on the other hand, is a distributed computing library for big data processing, built on top of apache spark. it is designed to handle large-scale data processing tasks across a cluster of machines.
resilient distributed datasets (rdds): pyspark operates on rdds, which are fault-tolerant distributed collections of objects. rdds enable parallel processing of data across a cluster.
dataframe and sql support: similar to pandas, pyspark also supports dataframes, providing a high-level api for distributed data manipulation. it also allows querying data using sql.
built-in machine learning libraries: pyspark includes mllib, a scalable machine learning library, making it suitable for machine learning tasks on large datasets.
pandas:
pyspark:
let's explore a simple example to showcase the difference between pandas and pyspark using a hypothetical dataset.
in summary, pandas is well-suited for in-memory data manipulation on sma ...
#python pandas documentation
#python pandas install
#python pandas read csv
#python pandas library
#python pandas dataframe
Related videos on our channel:
python pandas documentation
python pandas install
python pandas read csv
python pandas library
python pandas dataframe
python pandas read excel
python pandas
python pandas rename column
python pandas cheat sheet
python pandas tutorial
python pyspark install
python pyspark
python pyspark resume
python pyspark read csv
python pyspark tutorial
python pyspark example
python pyspark cheat sheet
python pyspark package
 0:03:53
0:03:53
 0:01:54
0:01:54
 0:14:49
0:14:49
 0:11:32
0:11:32
 0:03:45
0:03:45
 0:09:09
0:09:09
 0:01:01
0:01:01
 0:21:00
0:21:00
 0:10:51
0:10:51
 0:31:21
0:31:21
 0:00:24
0:00:24
 0:03:26
0:03:26
 0:03:14
0:03:14
 0:06:13
0:06:13
 0:08:31
0:08:31
 0:05:55
0:05:55
 1:49:02
1:49:02
 0:04:48
0:04:48
 0:00:46
0:00:46
 0:05:48
0:05:48
 0:10:00
0:10:00
 0:20:19
0:20:19
 0:02:53
0:02:53
 0:00:53
0:00:53