filmov
tv
Graph Data Structure 6. The A* Pathfinding Algorithm

Показать описание
This is the sixth in a series of videos about the graph data structure. It includes a step by step walkthrough of the A* pathfinding algorithm (pronounced A Star) for a weighted, undirected graph. The A* pathfinding algorithm, and its numerous variations, is widely used in applications such as games programming, natural language processing, financial trading systems, town planning and even space exploration. This video demonstrates why the A* pathfinding algorithm may be more appropriate and more efficient than Dijkstra’s shortest path algorithm for many applications, because it is focussed on finding the shortest path between only two particular vertices. The video explains the need for an admissible heuristic, that is, a suitable estimate of the distance between each vertex in the graph and the destination vertex; the example shown here makes use of Manhattan distances for this purpose, calculated on the basis of the grid co-ordinates of each vertex. A description of the pseudocode that leads to an implementation of the A* pathfinding algorithm is also included.
When you watch this example, you will see there are occasions when the f values of some open vertices are the same, so the next current vertex is selected from these “for no particular reason”. As pointed out, making one choice or another could have a profound effect on the course of events that follow, but that very much depends on how the algorithm is implemented, and the anatomy of the graph being searched. The search described in this video concludes when the destination vertex is a neighbour of the current vertex - and it shares the lowest f value. Conceivably, another open vertex could have had a lower f value than the destination at this stage, so the search for a shorter path would continue. Again, exactly how the algorithm finishes is a matter of implementation. If you investigate this subject further, you will discover there are lots of ways the algorithm can be adapted. Using a priority queue for the open vertices is one way, pre-processing the graph data to calculate the h values is another. The basic A* pathfinding algorithm descried here is really just a starting point.
When you watch this example, you will see there are occasions when the f values of some open vertices are the same, so the next current vertex is selected from these “for no particular reason”. As pointed out, making one choice or another could have a profound effect on the course of events that follow, but that very much depends on how the algorithm is implemented, and the anatomy of the graph being searched. The search described in this video concludes when the destination vertex is a neighbour of the current vertex - and it shares the lowest f value. Conceivably, another open vertex could have had a lower f value than the destination at this stage, so the search for a shorter path would continue. Again, exactly how the algorithm finishes is a matter of implementation. If you investigate this subject further, you will discover there are lots of ways the algorithm can be adapted. Using a priority queue for the open vertices is one way, pre-processing the graph data to calculate the h values is another. The basic A* pathfinding algorithm descried here is really just a starting point.
Graph Data Structure 6. The A* Pathfinding Algorithm
 0:05:17
0:05:17
Learn Graphs in 5 minutes 🌐
 0:10:52
0:10:52
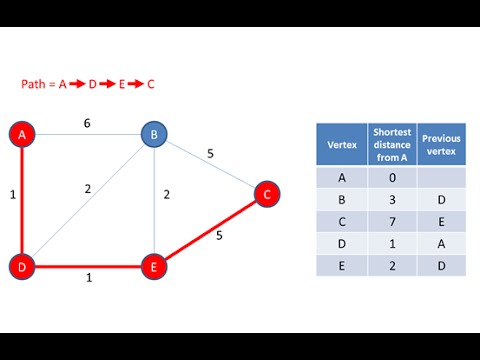
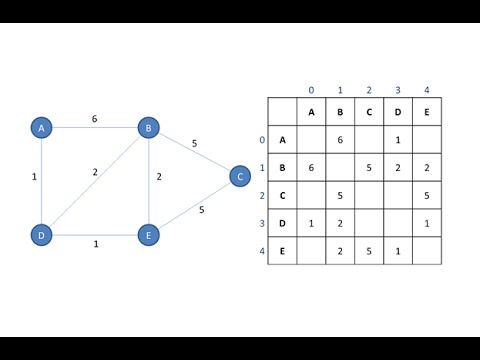
Graph Data Structure 4. Dijkstra’s Shortest Path Algorithm
 0:07:59
0:07:59
Graph Data Structure 1. Terminology and Representation (algorithms)
![#033 [Data Structures]](https://i.ytimg.com/vi/R74DnYySxv0/hqdefault.jpg) 0:22:32
0:22:32
#033 [Data Structures] - Introduction To Graph,Types Of Graph and Representation
 0:13:32
0:13:32
Graph Data Structure | Illustrated Data Structures
 0:20:27
0:20:27
6.2 BFS and DFS Graph Traversals| Breadth First Search and Depth First Search | Data structures
 0:04:53
0:04:53
Graph Data Structure Intro (inc. adjacency list, adjacency matrix, incidence matrix)
 2:12:14
2:12:14
TEAS 7 Math - ALL IN ONE Webinar - Measurement and Data - October 2024
 2:12:19
2:12:19
Graph Algorithms for Technical Interviews - Full Course
 6:44:40
6:44:40
Algorithms Course - Graph Theory Tutorial from a Google Engineer
 0:06:37
0:06:37
Shortest Path in Unweighted graph | Graph #6
 0:15:16
0:15:16
Data structures: Properties of Graphs
 0:06:39
0:06:39
Degree of a vertex in Graph | Graph Theory #6
 0:32:27
0:32:27
Graph Introduction - Data Structures & Algorithms Tutorials In Python #12
 0:16:26
0:16:26
Introduction to Graph Theory: A Computer Science Perspective
 0:13:01
0:13:01
Top 5 Most Common Graph Algorithms for Coding Interviews
 0:06:41
0:06:41
Learn Breadth First Search in 6 minutes ↔️
 0:03:44
0:03:44
Graph Types Directed and Undirected Graph
 0:20:44
0:20:44
Graph Data Structure | Part 6 | Breadth First Search and Traversal | BFS
 0:00:42
0:00:42
4 Ways to Represent Graph Data Structures - Edge List, Adjacency List / Matrix, Object & Pointer
 0:21:33
0:21:33
Graph Data Structure | Part 11 | Dijkstra's Algorithm | Shortest Path in Graph Step by Step Dem...
 0:04:21
0:04:21
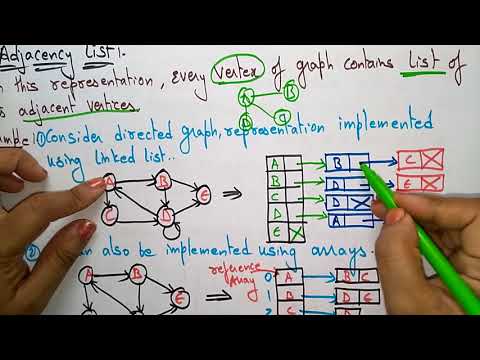
Adjacency list | Example | Graph representation | Data Structures | Lec-49 | Bhanu Priya
 0:00:50
0:00:50
Djikstra's Graph Algorithm: Single-Source Shortest Path
Комментарии