filmov
tv
Going Further with CUDA for Python Programmers
Показать описание
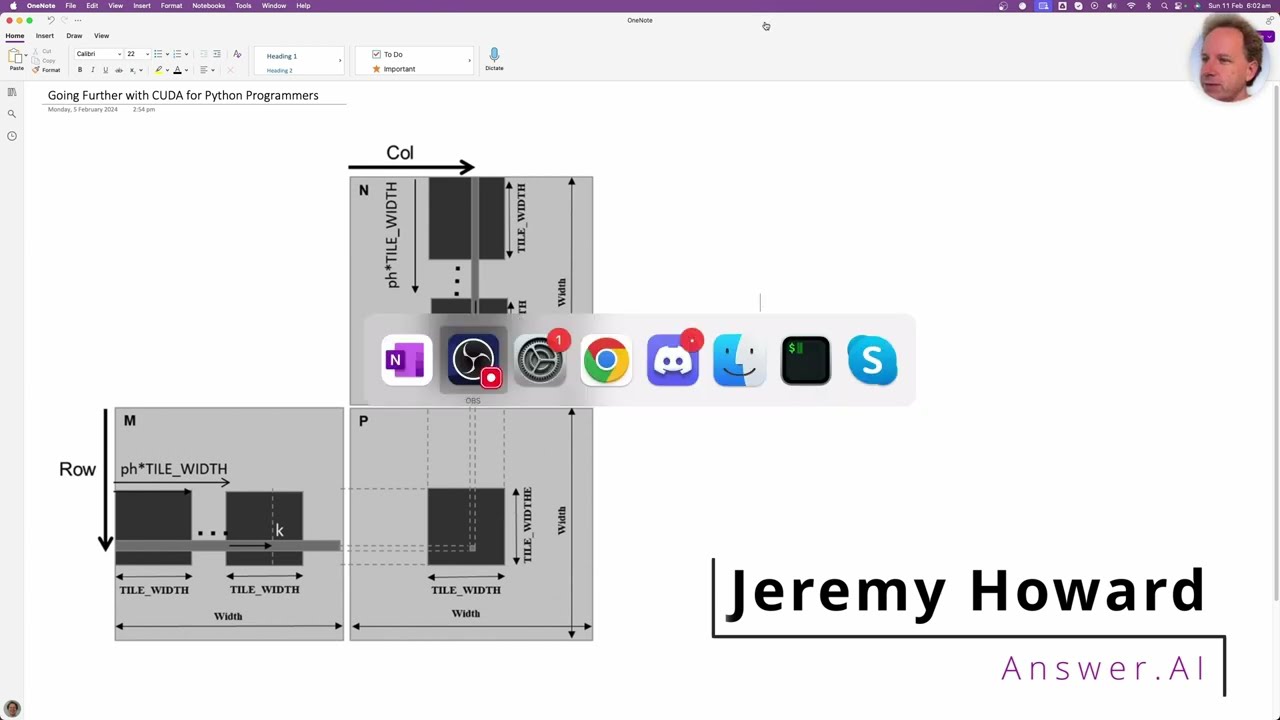
The video begins with foundational concepts by comparing shared memory to global memory and demonstrates strategies like tiling to address shared memory capacity limitations. It demonstrates core ideas through a matrix multiplication example.
Jeremy compares pure Python, Python with simulated 'shared memory', Numba, and raw CUDA implementations, using ChatGPT for guided code conversion. While initial Numba-based code may exhibit some overhead, it serves as a fast development pathway compared to raw CUDA.
## Resources
## Timestamps
- 0:00 Introduction to Optimized Matrix Multiplication
- 12:04 Shared Memory Techniques for CUDA
- 20:12 Implementing Shared Memory Optimization in Python
- 42:15 Translating Python to CUDA and Performance Considerations
- 55:55 Numba: Bringing Python and CUDA Together
- 1:11:46 The Future of AI in Coding
Thanks to @wolpumba4099 for initial summary and timestamps.
 1:17:34
1:17:34
Going Further with CUDA for Python Programmers
 1:17:56
1:17:56
Getting Started With CUDA for Python Programmers
 0:11:41
0:11:41
What is CUDA? - Computerphile
 0:00:25
0:00:25
Working with CUDA, Device and GPU / CPU in PyTorch #shorts
 0:01:00
0:01:00
The Power of CUDA in AI Development
 0:13:33
0:13:33
CUDA Explained - Why Deep Learning uses GPUs
 11:55:11
11:55:11
CUDA Programming Course – High-Performance Computing with GPUs
 0:00:56
0:00:56
Lightning Fast Mandelbrot Generation With PyTorch And CUDA
 0:21:06
0:21:06
Zen, CUDA, and Tensor Cores - Part 1
 0:19:11
0:19:11
CUDA Simply Explained - GPU vs CPU Parallel Computing for Beginners
 0:07:06
0:07:06
AMD stopped funding this project and CUDA dev
 0:00:47
0:00:47
🚀 Jensen Huang Reveals Nvidia's Secret to Decades of CUDA Compatibility! 💥 #shorts #youtube #nv...
 0:01:53
0:01:53
Is CUDA still a moat for NVIDIA? #aihardware #aichips #podcast
 0:00:12
0:00:12
UNRESTORED!! 1970 Plymouth AAR CUDA #shorts #mopar #musclecar
 0:00:14
0:00:14
Subscribe for more! #mopar #automobile #dodge #diy #restomod #car #restoration #cuda #musclecar
 0:00:30
0:00:30
NVIDIA's Stephen Jones: All of CUDA's Elements Work Together, and That's What Makes i...
 0:00:32
0:00:32
Mecum Auction No Reserve 1973 Cuda!
 0:44:05
0:44:05
CUDA: New Features and Beyond | NVIDIA GTC 2025
 0:15:03
0:15:03
Technical Demo from Supercomputing '11: Introduction to CUDA C and GPU Computing
 0:00:22
0:00:22
NVIDIA's Stephen Jones: CUDA's Users Wrote Millions of Lines of Code
 0:00:31
0:00:31
1970 Plymouth Cuda (V21558) #1970 #Plymouth #Cuda #ForSale #Classicars #Tribute #440 #restored
 0:43:32
0:43:32
CUDA in your Python Parallel Programming on the GPU - William Horton
 0:12:53
0:12:53
Mini Project: How to program a GPU? | CUDA C/C++
 0:46:57
0:46:57
Cuda 8 and Beyond
Комментарии