filmov
tv
Apache Spark Tutorial: Introduction To Spark SQL, Datasets, and DataFrames

Показать описание
Welcome to the captivating 11th video of our comprehensive Apache Spark tutorial series! In this session, we dive into the world of Spark SQL, Datasets, and DataFrames, where we unlock the full potential of structured data processing in Apache Spark.
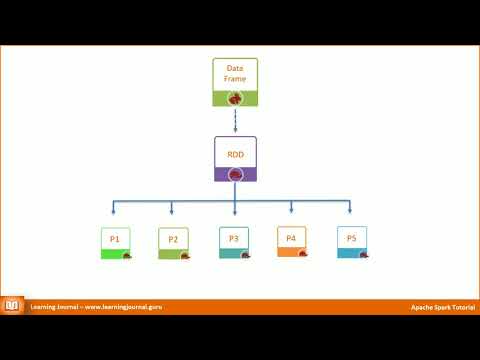
In this session, we take you on a journey through the rich capabilities of Spark SQL, the module that enables SQL-like querying and processing of structured data in Spark. We explore the seamless integration between Spark SQL, Datasets, and DataFrames, providing you with a unified and intuitive programming model for working with structured data.
With clear explanations, practical examples, and hands-on exercises, we guide you through the powerful SQL capabilities of Spark, empowering you to express complex data transformations and queries with ease. We demonstrate how Datasets and DataFrames extend the benefits of strong typing and optimized execution from Spark SQL, allowing for high-performance, distributed data processing.
Throughout this session, you'll learn how to leverage Spark's Catalyst optimizer and the Tungsten execution engine to efficiently process structured data. We'll explore the advanced functionalities and optimizations provided by DataFrames, enabling you to perform a wide range of data manipulations, aggregations, and analytics tasks.
Whether you're a beginner or an experienced Spark user, this session is a must-watch for mastering the art of Spark SQL, Datasets, and DataFrames. Subscribe to our channel and unlock the full potential of structured data processing in Apache Spark, empowering yourself with the skills to handle complex data workflows and unleash the power of Spark's structured data processing capabilities.
In this session, we take you on a journey through the rich capabilities of Spark SQL, the module that enables SQL-like querying and processing of structured data in Spark. We explore the seamless integration between Spark SQL, Datasets, and DataFrames, providing you with a unified and intuitive programming model for working with structured data.
With clear explanations, practical examples, and hands-on exercises, we guide you through the powerful SQL capabilities of Spark, empowering you to express complex data transformations and queries with ease. We demonstrate how Datasets and DataFrames extend the benefits of strong typing and optimized execution from Spark SQL, allowing for high-performance, distributed data processing.
Throughout this session, you'll learn how to leverage Spark's Catalyst optimizer and the Tungsten execution engine to efficiently process structured data. We'll explore the advanced functionalities and optimizations provided by DataFrames, enabling you to perform a wide range of data manipulations, aggregations, and analytics tasks.
Whether you're a beginner or an experienced Spark user, this session is a must-watch for mastering the art of Spark SQL, Datasets, and DataFrames. Subscribe to our channel and unlock the full potential of structured data processing in Apache Spark, empowering yourself with the skills to handle complex data workflows and unleash the power of Spark's structured data processing capabilities.
 0:38:20
0:38:20
 0:15:40
0:15:40
 0:10:47
0:10:47
 0:17:16
0:17:16
 0:02:39
0:02:39
 1:49:02
1:49:02
 0:48:54
0:48:54
 0:02:53
0:02:53
 0:27:26
0:27:26
 7:15:32
7:15:32
 0:07:40
0:07:40
 0:13:32
0:13:32
 0:04:37
0:04:37
 3:00:01
3:00:01
 0:30:33
0:30:33
 0:32:23
0:32:23
 0:36:34
0:36:34
 1:56:02
1:56:02
 0:25:48
0:25:48
 6:41:07
6:41:07
 0:14:00
0:14:00
 0:04:21
0:04:21
 7:48:37
7:48:37
 0:08:56
0:08:56