filmov
tv
Building Scalable Retrieval System with Two-Tower Models | Query-Item Retrieval Recsys Model | ML AI

Показать описание
#datascience #machinelearning #artificialintelligence #recsys #recommendations #amazon
Explore the power of Two-Tower Model Architecture in this YouTube video! Discover how this deep learning approach is revolutionizing retrieval tasks for search and recommendation systems. Whether one is in e-commerce, content search, or social networking, Two-Tower Models offer incredible flexibility and scalability.
In this video, we will take a deep dive into the realm of Two-Tower Models, which comprise two distinct towers—one for queries and one for items. These models have the potential to revolutionize various recommendation and search tasks, whether it's finding relevance between users and products, queries and documents, people and people, or users and images/videos, among others. The versatility of the two-tower architecture extends to any pair of entities we wish to analyze.
We will also demonstrate the process of training these neural networks using Amazon's open-source datasets to address query-item retrieval challenges, making them highly adaptable to the specific requirements. Once trained, these models generate embeddings for the entities involved, facilitating the efficient retrieval of relevant items at scale.
In the context of e-commerce, we will discuss the limitations of relying solely on word matching and why it's imperative to take into account other factors and actual purchase behavior to enhance the retrieval of more relevant items. We will explore the concept of fine-tuning embeddings by incorporating additional signals such as category, price, ratings, reviews, and personalized data. This approach significantly boosts the scalability and accuracy of your retrieval system.
In this video, we will go through the process of building a Two-Tower Search-Item Retrieval model from scratch using an open-source Amazon dataset in details, allowing one to witness firsthand how this architecture can create a highly effective and scalable retrieval system. The codes and all the relevant links are provided.
#datascience #machinelearning #statistics #deeplearning #programming #python #datatrek #youtube #interview #interviewpreparation #interviewquestions #datascientist #dataanalytics #machinelearningengineer #datasciencejobs #datasciencetraining #datasciencecourse #datascienceenthusiast #career #careeropportunities #careergrowth #careerdevelopment #datascienceenthusiast #interviewing #ml #ai
#datatrek #datascience #machinelearning #statistics #deeplearning #ai
About DataTrek Series
Explore the power of Two-Tower Model Architecture in this YouTube video! Discover how this deep learning approach is revolutionizing retrieval tasks for search and recommendation systems. Whether one is in e-commerce, content search, or social networking, Two-Tower Models offer incredible flexibility and scalability.
In this video, we will take a deep dive into the realm of Two-Tower Models, which comprise two distinct towers—one for queries and one for items. These models have the potential to revolutionize various recommendation and search tasks, whether it's finding relevance between users and products, queries and documents, people and people, or users and images/videos, among others. The versatility of the two-tower architecture extends to any pair of entities we wish to analyze.
We will also demonstrate the process of training these neural networks using Amazon's open-source datasets to address query-item retrieval challenges, making them highly adaptable to the specific requirements. Once trained, these models generate embeddings for the entities involved, facilitating the efficient retrieval of relevant items at scale.
In the context of e-commerce, we will discuss the limitations of relying solely on word matching and why it's imperative to take into account other factors and actual purchase behavior to enhance the retrieval of more relevant items. We will explore the concept of fine-tuning embeddings by incorporating additional signals such as category, price, ratings, reviews, and personalized data. This approach significantly boosts the scalability and accuracy of your retrieval system.
In this video, we will go through the process of building a Two-Tower Search-Item Retrieval model from scratch using an open-source Amazon dataset in details, allowing one to witness firsthand how this architecture can create a highly effective and scalable retrieval system. The codes and all the relevant links are provided.
#datascience #machinelearning #statistics #deeplearning #programming #python #datatrek #youtube #interview #interviewpreparation #interviewquestions #datascientist #dataanalytics #machinelearningengineer #datasciencejobs #datasciencetraining #datasciencecourse #datascienceenthusiast #career #careeropportunities #careergrowth #careerdevelopment #datascienceenthusiast #interviewing #ml #ai
#datatrek #datascience #machinelearning #statistics #deeplearning #ai
About DataTrek Series
 0:26:14
0:26:14
Building Scalable Retrieval System with Two-Tower Models | Query-Item Retrieval Recsys Model | ML AI
 0:18:35
0:18:35
Building Production-Ready RAG Applications: Jerry Liu
 0:11:39
0:11:39
How Instagram Stores BILLIONS of Videos
 0:48:55
0:48:55
From Zero to a Hundred Billion: Building Scalable Real-Time Event Processing at DoorDash
 0:35:07
0:35:07
'Building Scalable Stateful Services' by Caitie McCaffrey
 0:00:21
0:00:21
Built-in vector search and limitless scalability for generative AI and real-time workloads.
 0:00:05
0:00:05
How to Build an Scalable and Robust Generative AI Application Ecosystem
 0:02:53
0:02:53
Build a Large Language Model AI Chatbot using Retrieval Augmented Generation
 0:53:45
0:53:45
Build Contextual Retrieval with Anthropic and Pinecone
 0:37:09
0:37:09
Real-Time Search and Recommendation at Scale Using Embeddings and Hopsworks
 0:01:34
0:01:34
Scalability: How we build scalable web applications based on a NoSQL database architectur
 0:06:56
0:06:56
Efficient serving with ScaNN for retrieval (Building recommendation systems with TensorFlow)
 0:01:01
0:01:01
How to build scalable AI products: Join our upcoming seminar!
 0:05:48
0:05:48
Cache Systems Every Developer Should Know
 0:11:18
0:11:18
Building Scalable Cross-Modal Search with Ray | Ray Summit 2024
 0:08:42
0:08:42
7 Must-know Strategies to Scale Your Database
 0:03:39
0:03:39
System Design: Why is single-threaded Redis so fast?
 0:53:55
0:53:55
Scaling AI Beyond Vectors: Building Smarter, Faster Systems for Retrieval-Augmented Generation (RAG)
 0:00:19
0:00:19
How to build scalable apps
 0:46:33
0:46:33
RAG at scale: production-ready GenAI apps with Azure AI Search | BRK108
 0:11:41
0:11:41
20 System Design Concepts Explained in 10 Minutes
 0:05:57
0:05:57
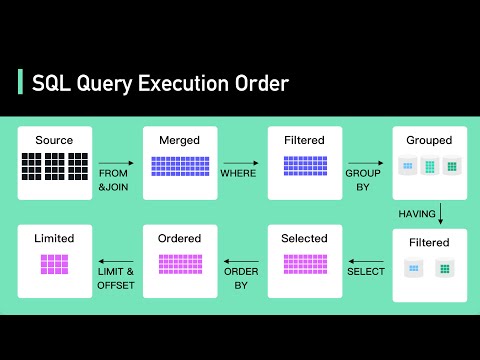
Secret To Optimizing SQL Queries - Understand The SQL Execution Order
 0:02:26
0:02:26
Building Scalable Server Architecture with Python
 0:27:57
0:27:57
Building Scalable Graph RAG Pipelines with Kubeflow for Enterprise
Комментарии