filmov
tv
From Basic to Advanced Aggregate Operators in Apache Spark SQL 2 2 by Examples and their Catalyst Op

Показать описание
"There are many different aggregate operators in Spark SQL. They range from the very basic groupBy and not so basic groupByKey that shines bright in Apache Spark Structured Streaming’s stateful aggregations, including the more advanced cube, rollup and pivot to my beloved windowed aggregations. It’s unbelievable how different the performance characteristic they have, even for the same use cases.
What is particularly interesting is the comparison of the simplicity and performance of windowed aggregations vs groupBy. And that’s just Spark SQL alone. Then there is Spark Structured Streaming that has put groupByKey operator at the forefront of stateful stream processing (and to my surprise as the performance might not be that satisfactory).
This deep-dive talk is going to show all the different use cases for the aggregate operators and functions as well as their performance differences in Spark SQL 2.2 and beyond. Code and fun included!
Session hashtag: #EUdd5"
About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
What is particularly interesting is the comparison of the simplicity and performance of windowed aggregations vs groupBy. And that’s just Spark SQL alone. Then there is Spark Structured Streaming that has put groupByKey operator at the forefront of stateful stream processing (and to my surprise as the performance might not be that satisfactory).
This deep-dive talk is going to show all the different use cases for the aggregate operators and functions as well as their performance differences in Spark SQL 2.2 and beyond. Code and fun included!
Session hashtag: #EUdd5"
About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
 0:31:24
0:31:24
 0:34:45
0:34:45
 0:06:00
0:06:00
 0:05:44
0:05:44
 3:10:19
3:10:19
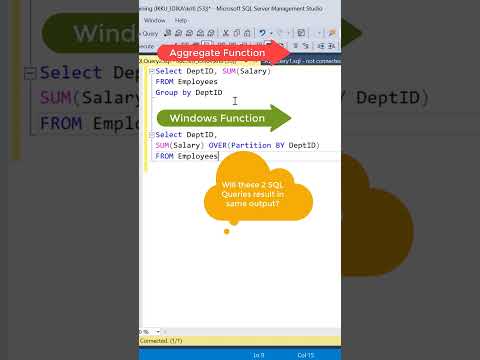 0:00:37
0:00:37
 1:58:14
1:58:14
 0:44:57
0:44:57
 0:19:36
0:19:36
 0:05:00
0:05:00
 0:08:37
0:08:37
 0:32:33
0:32:33
 0:08:02
0:08:02
 0:00:46
0:00:46
 0:11:47
0:11:47
 0:37:12
0:37:12
 0:24:55
0:24:55
 0:00:36
0:00:36
 0:08:46
0:08:46
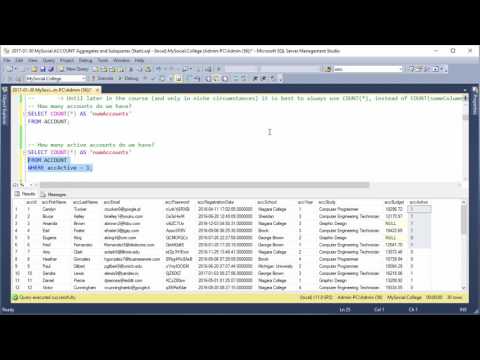 0:04:46
0:04:46
 0:00:47
0:00:47
 0:09:25
0:09:25
 0:31:40
0:31:40
 0:24:09
0:24:09