filmov
tv
Resolving .txt File Encoding Issues: Understanding UTF-8 and UTF-16 Differences

Показать описание
Discover how to handle encoding issues with `.txt` files in C# . Learn why manually saving files can affect code execution and how to solve character encoding problems effectively.
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Code Treats .txt File Differently When Saved
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Why Does My .txt File Behave Differently When Saved?
Working with text files in programming can often lead to unexpected behavior, especially when it comes to encoding. If you've encountered a situation where your C# code successfully processes a .txt file only after manually saving it, you're not alone. This can be a frustrating issue, and understanding why it happens is crucial to effectively solve it. In this guide, we’ll explore the potential reasons behind this phenomenon and how to fix it.
The Problem
You might have a .txt file that looks like this:
[[See Video to Reveal this Text or Code Snippet]]
Your goal is to reduce the extra whitespace in this file using the following code:
[[See Video to Reveal this Text or Code Snippet]]
However, if you run the code directly on the file without any alterations, it fails to function properly. Interestingly, merely opening the file and saving it again (even without making any changes) allows your code to work as intended. This disparity raises a crucial question: What is happening with the file's encoding?
Understanding UTF-8 vs. UTF-16 Encoding
The root of the issue often lies in the invisible characters introduced by different character encodings such as UTF-8 and UTF-16. These inclinations can cause your text file to behave unexpectedly when read by your program. Here’s how it works:
UTF-8: It is a variable-length encoding that can represent any character in the Unicode standard. It's generally preferred for text files since it's efficient and widely supported.
UTF-16: This encoding uses a fixed length of 2 bytes for each character, which can lead to the introduction of control characters or unused code points in the file.
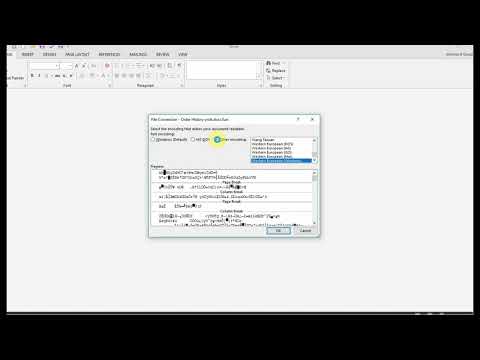
When your text file is created or saved with a particular encoding, it can introduce non-visible characters (control characters) that affect how text is processed. When you manually save the file, your text editor may convert it to a more consistent format, resolving invisible formatting issues.
The Solution
To ensure your code works consistently on any .txt file, regardless of its encoding, you can modify your approach to strip out those invisible control characters using regular expressions. Here’s how you can do it:
Updated Code
Instead of using ReadAllText and splitting by lines, you can read the lines directly and cleanse them of unwanted characters. Update your code as follows:
[[See Video to Reveal this Text or Code Snippet]]
Explanation of Changes
File.ReadAllLines: Reads all lines of the file while respecting the file's line endings, which can help maintain proper formatting.
Regular Expression @ "\p{C}+ ": This regex targets any control character, making it effective at removing hidden formatting that might disrupt your text processing.
Why This Works
By using this approach, your code will no longer be affected by invisible control characters. Whether your file is saved in UTF-8 or UTF-16, the cleansing operation ensures that only the desired characters remain, thus streamlining your whitespace reduction process and eliminating frustration.
Conclusion
Handling text files and their encoding can be tricky, especially when control characters come into play. If you find that your .txt files behave unexpectedly, consider the role of encoding and the presence of invisible characters. By implementing a more robust method to handle these cases, you can ensure your code runs smoothly, regardless of how the file was saved. Happy coding!
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Code Treats .txt File Differently When Saved
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Why Does My .txt File Behave Differently When Saved?
Working with text files in programming can often lead to unexpected behavior, especially when it comes to encoding. If you've encountered a situation where your C# code successfully processes a .txt file only after manually saving it, you're not alone. This can be a frustrating issue, and understanding why it happens is crucial to effectively solve it. In this guide, we’ll explore the potential reasons behind this phenomenon and how to fix it.
The Problem
You might have a .txt file that looks like this:
[[See Video to Reveal this Text or Code Snippet]]
Your goal is to reduce the extra whitespace in this file using the following code:
[[See Video to Reveal this Text or Code Snippet]]
However, if you run the code directly on the file without any alterations, it fails to function properly. Interestingly, merely opening the file and saving it again (even without making any changes) allows your code to work as intended. This disparity raises a crucial question: What is happening with the file's encoding?
Understanding UTF-8 vs. UTF-16 Encoding
The root of the issue often lies in the invisible characters introduced by different character encodings such as UTF-8 and UTF-16. These inclinations can cause your text file to behave unexpectedly when read by your program. Here’s how it works:
UTF-8: It is a variable-length encoding that can represent any character in the Unicode standard. It's generally preferred for text files since it's efficient and widely supported.
UTF-16: This encoding uses a fixed length of 2 bytes for each character, which can lead to the introduction of control characters or unused code points in the file.
When your text file is created or saved with a particular encoding, it can introduce non-visible characters (control characters) that affect how text is processed. When you manually save the file, your text editor may convert it to a more consistent format, resolving invisible formatting issues.
The Solution
To ensure your code works consistently on any .txt file, regardless of its encoding, you can modify your approach to strip out those invisible control characters using regular expressions. Here’s how you can do it:
Updated Code
Instead of using ReadAllText and splitting by lines, you can read the lines directly and cleanse them of unwanted characters. Update your code as follows:
[[See Video to Reveal this Text or Code Snippet]]
Explanation of Changes
File.ReadAllLines: Reads all lines of the file while respecting the file's line endings, which can help maintain proper formatting.
Regular Expression @ "\p{C}+ ": This regex targets any control character, making it effective at removing hidden formatting that might disrupt your text processing.
Why This Works
By using this approach, your code will no longer be affected by invisible control characters. Whether your file is saved in UTF-8 or UTF-16, the cleansing operation ensures that only the desired characters remain, thus streamlining your whitespace reduction process and eliminating frustration.
Conclusion
Handling text files and their encoding can be tricky, especially when control characters come into play. If you find that your .txt files behave unexpectedly, consider the role of encoding and the presence of invisible characters. By implementing a more robust method to handle these cases, you can ensure your code runs smoothly, regardless of how the file was saved. Happy coding!
 0:01:41
0:01:41
 0:01:29
0:01:29
 0:06:02
0:06:02
 0:01:40
0:01:40
 0:01:32
0:01:32
 0:03:26
0:03:26
 0:01:44
0:01:44
 0:00:39
0:00:39
 0:01:43
0:01:43
 0:01:43
0:01:43
 0:01:28
0:01:28
 0:01:24
0:01:24
 0:01:16
0:01:16
 0:01:25
0:01:25
 0:04:38
0:04:38
 0:01:44
0:01:44
 0:01:53
0:01:53
 0:05:31
0:05:31
 0:01:37
0:01:37
 0:01:32
0:01:32
 0:01:06
0:01:06
 0:01:25
0:01:25
 0:01:47
0:01:47
 0:01:36
0:01:36