filmov
tv
Synthetic Gradients Explained

Показать описание
DeepMind released an optimization strategy that could become the most popular approach for training very deep neural networks, even more so than backpropagation. I don't think it got enough love, so i'm going to explain how it works myself and why i think it's so cool. Already know how backpropagation works? Skip to 14:10
Code for this video:
Please Subscribe! And like. And comment. Thats what keeps me going.
Follow me on:
Snapchat: @llSourcell
More learning resources:
Join us in the Wizards Slack channel:
Signup for my newsletter for exciting updates in the field of AI:
Code for this video:
Please Subscribe! And like. And comment. Thats what keeps me going.
Follow me on:
Snapchat: @llSourcell
More learning resources:
Join us in the Wizards Slack channel:
Signup for my newsletter for exciting updates in the field of AI:
 0:27:16
0:27:16
Synthetic Gradients Explained
 0:20:25
0:20:25
Synthetic Gradients Tutorial - How to Speed Up Deep Learning Training
 0:41:19
0:41:19
Synthetic Gradients – Decoupling Layers of a Neural Nets: Anuj Gupta
 0:03:06
0:03:06
Gradient Descent in 3 minutes
 0:20:33
0:20:33
Gradient descent, how neural networks learn | DL2
 0:07:05
0:07:05
Gradient Descent Explained
 0:00:16
0:00:16
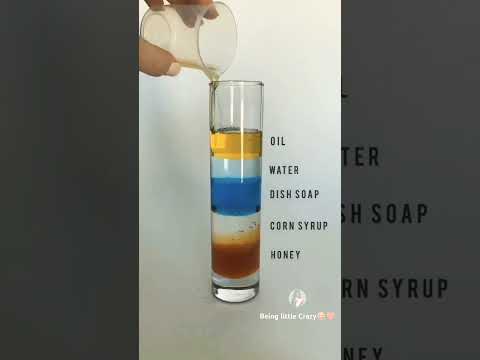
| colourful liquid density gradient | layers of liquid in glass |Awesome science experiment
 0:00:52
0:00:52
Gradient Descent Machine Learning
 0:07:43
0:07:43
Vanishing & Exploding Gradient explained | A problem resulting from backpropagation
 0:00:50
0:00:50
Mastering Gradient Descent | The Heart of Machine Learning Algorithms Explained
 0:01:00
0:01:00
Neural Networks explained in 60 seconds!
 0:01:01
0:01:01
Learning to Generate 3D Training Data Through Hybrid Gradient
 0:00:53
0:00:53
What is Gradient Descent in Machine Learning?
 0:05:25
0:05:25
An Old Problem - Ep. 5 (Deep Learning SIMPLIFIED)
 0:14:30
0:14:30
Tutorial 7- Vanishing Gradient Problem
 0:00:52
0:00:52
Gradient Boosting Explained #datascience #machinelearning #statistics #boosting #math
 0:12:47
0:12:47
Backpropagation, step-by-step | DL3
 0:15:39
0:15:39
Gradient descent simple explanation|gradient descent machine learning|gradient descent algorithm
 0:00:09
0:00:09
Exploding Gradients Explained: The Hidden Danger in Deep Learning!
 0:00:39
0:00:39
Gradient Descent|Machine Learning
 0:03:29
0:03:29
Model interpretability with Integrated Gradients - Keras Code Examples
 0:01:00
0:01:00
Gradient Descent Explained: How It Works and Finds the Minimum of Complex Functions #CodeMonarch
 0:09:39
0:09:39
AI Explained Video Series - Learn about Explainable AI and MLOps: What are Integrated Gradients?
 0:03:21
0:03:21
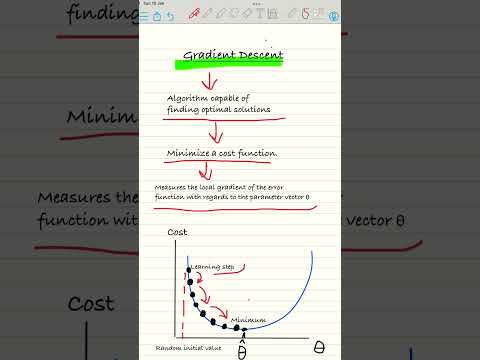
AI Explained – Gradient Descent | A Machine Learning Tool
Комментарии