filmov
tv
Efficient Inference of Extremely Large Transformer Models
Показать описание
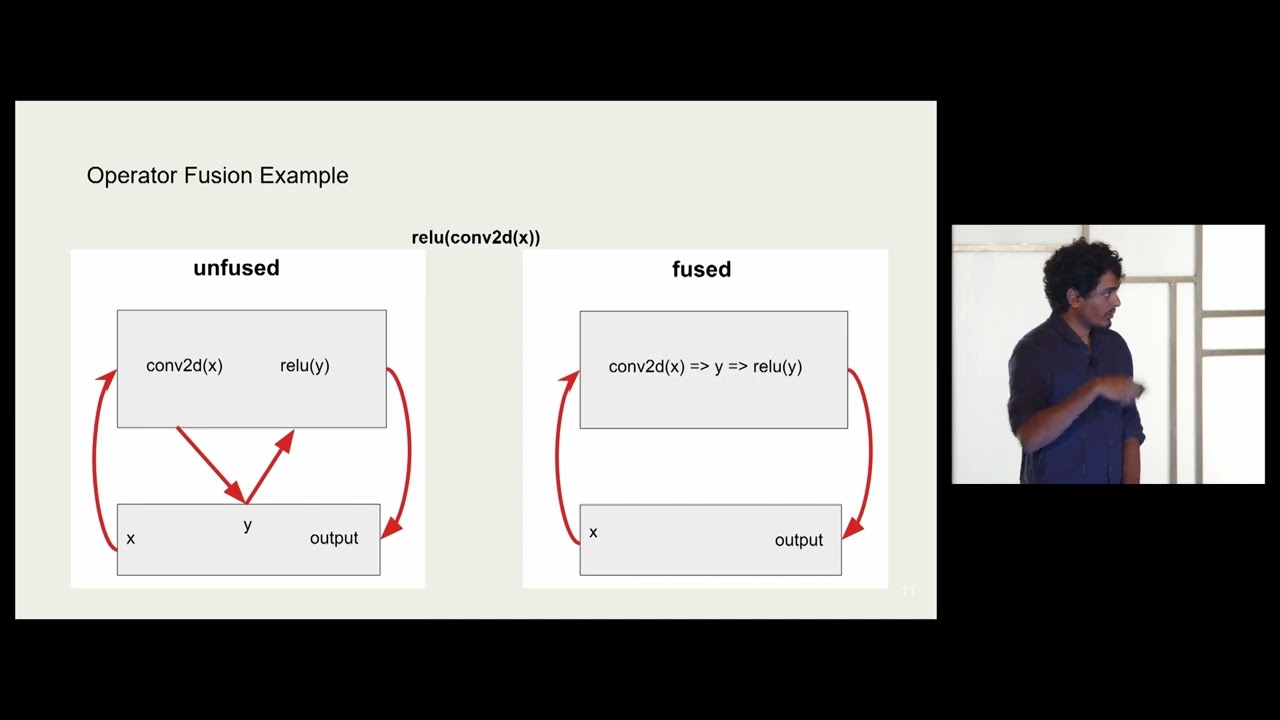
The rise of transformer-based language models has seen a boom in model sizes, since these models’ performance scales extremely well with size. With this comes the challenge to develop solutions to make inference on these models more efficient. We'll show how these behemoth multi-billion-parameter models are optimized for production and how the inference tech stack is established. We'll cover the key ingredients in making these models faster, smaller, and more cost-effective, including model compression, efficient attention, and optimal model parallelism.
Bharat Venkitesh, Senior Machine Learning Engineer, Cohere
Bharat Venkitesh, Senior Machine Learning Engineer, Cohere
 0:28:16
0:28:16
 0:33:39
0:33:39
 0:30:08
0:30:08
 0:00:31
0:00:31
 0:06:28
0:06:28
 2:15:57
2:15:57
 0:01:08
0:01:08
 0:53:35
0:53:35
 11:04:16
11:04:16
 1:02:05
1:02:05
![[ICML 2024] InferCept:](https://i.ytimg.com/vi/iOs1b08V2yE/hqdefault.jpg) 0:05:28
0:05:28
 0:00:44
0:00:44
 0:19:46
0:19:46
 0:16:04
0:16:04
 0:04:11
0:04:11
 0:15:51
0:15:51
 0:08:45
0:08:45
 0:00:56
0:00:56
![[AUTOML23] Cost-Effective Hyperparameter](https://i.ytimg.com/vi/xx-bXUFBa98/hqdefault.jpg) 0:09:18
0:09:18
 0:18:59
0:18:59
 0:52:01
0:52:01
![[REFAI Seminar 03/30/23]](https://i.ytimg.com/vi/smDC_mOGQ5U/hqdefault.jpg) 1:06:53
1:06:53
 0:00:30
0:00:30
 0:11:54
0:11:54