filmov
tv
Quantization vs Pruning vs Distillation: Optimizing NNs for Inference

Показать описание
Four techniques to optimize the speed of your model's inference process:
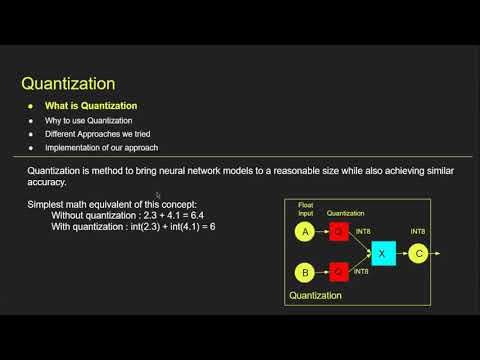
0:38 - Quantization
5:59 - Pruning
9:48 - Knowledge Distillation
13:00 - Engineering Optimizations
References:
 0:19:46
0:19:46
Quantization vs Pruning vs Distillation: Optimizing NNs for Inference
 0:15:34
0:15:34
Quantization in deep learning | Deep Learning Tutorial 49 (Tensorflow, Keras & Python)
 0:02:52
0:02:52
AI Model Compression (Quantization, Pruning and Knowledge Distillation)
 0:02:01
0:02:01
Pruning a neural Network for faster training times
 0:03:09
0:03:09
PQK: Model Compression via Pruning, Quantization, and Knowledge Distillation - (3 minutes introd...
 0:03:29
0:03:29
Smaller Models Are Better Ones: Prune and Quantize
 0:00:59
0:00:59
Unstructured vs Structured Pruning in Neural Networks #shorts
 0:00:52
0:00:52
✂️ Mastering Model Optimization: Distillation, Pruning, and Quantization! 🚀 #optimization #genai...
 1:07:07
1:07:07
Lecture 03 - Pruning and Sparsity (Part I) | MIT 6.S965
 0:04:10
0:04:10
Knowledge Distillation in Deep Neural Network
 0:22:55
0:22:55
Pruning and Model Compression
 1:11:43
1:11:43
Lecture 05 - Quantization (Part I) | MIT 6.S965
 0:16:40
0:16:40
Neural Network Compression – Dmitri Puzyrev
 0:09:51
0:09:51
Knowledge Distillation in Deep Learning - Basics
![[Part 1] A](https://i.ytimg.com/vi/L1uuKPxNsHE/hqdefault.jpg) 0:10:51
0:10:51
[Part 1] A Crash Course on Model Compression for Data Scientists
 1:04:21
1:04:21
CMU Advanced NLP Fall 2024 (11): Distillation, Quantization, and Pruning
 1:14:29
1:14:29
CMU Advanced NLP 2024 (11): Distillation, Quantization, and Pruning
 0:16:49
0:16:49
Better not Bigger: Distilling LLMs into Specialized Models
 0:05:17
0:05:17
Learning Highly Sparse Deep Neural Networks through Pruning and Quantization
 1:31:15
1:31:15
Advanced Machine Learning with Neural Networks 2021 - Class 8 - Quantization and pruning
 0:04:41
0:04:41
ICLR Paper: Learn Step Size Quantization
 0:30:28
0:30:28
Lecture 12.2 - Network Pruning, Quantization, Knowledge Distillation
 0:02:58
0:02:58
structured vs unstructured pruning in PyTorch
 0:13:04
0:13:04
Quantization in Deep Learning (LLMs)
Комментарии