filmov
tv
What is Q-Learning (back to basics)

Показать описание
#qlearning #qstar #rlhf
What is Q-Learning and how does it work? A brief tour through the background of Q-Learning, Markov Decision Processes, Deep Q-Networks, and other basics necessary to understand Q* ;)
OUTLINE:
0:00 - Introduction
2:00 - Reinforcement Learning
7:00 - Q-Functions
19:00 - The Bellman Equation
26:00 - How to learn the Q-Function?
38:00 - Deep Q-Learning
42:30 - Summary
Links:
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
What is Q-Learning and how does it work? A brief tour through the background of Q-Learning, Markov Decision Processes, Deep Q-Networks, and other basics necessary to understand Q* ;)
OUTLINE:
0:00 - Introduction
2:00 - Reinforcement Learning
7:00 - Q-Functions
19:00 - The Bellman Equation
26:00 - How to learn the Q-Function?
38:00 - Deep Q-Learning
42:30 - Summary
Links:
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
 0:45:44
0:45:44
What is Q-Learning (back to basics)
 0:08:38
0:08:38
Q-Learning Explained - A Reinforcement Learning Technique
 0:06:48
0:06:48
Q-Learning Explained - Reinforcement Learning Tutorial
 0:11:44
0:11:44
What is Q* | Reinforcement learning 101 & Hypothesis
 0:10:11
0:10:11
Foundation of Q-learning | Temporal Difference Learning explained!
 0:11:28
0:11:28
Reinforcement Learning: Crash Course AI #9
 0:11:11
0:11:11
#1. Q Learning Algorithm Solved Example | Reinforcement Learning | Machine Learning by Mahesh Huddar
 0:10:50
0:10:50
Deep Q-Learning - Combining Neural Networks and Reinforcement Learning
 0:26:15
0:26:15
BACK TO HOMESCHOOL Q & A [How to Start Homeschooling] And Other Questions
 0:16:27
0:16:27
An introduction to Reinforcement Learning
 0:02:28
0:02:28
Reinforcement Learning Basics
 0:10:41
0:10:41
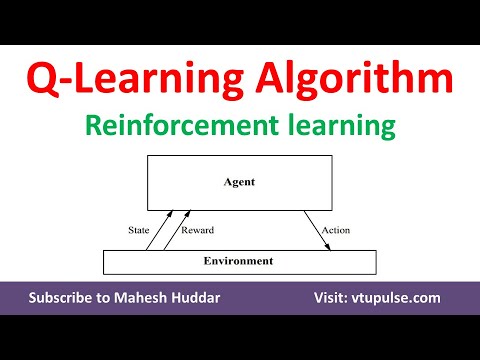
Q Learning Algorithm | Reinforcement learning | Machine Learning by Dr. Mahesh Huddar
 0:16:59
0:16:59
Foundations of Q-Learning
 0:18:19
0:18:19
Reinforcement Learning, by the Book
 0:21:15
0:21:15
Deep Reinforcement Learning: Neural Networks for Learning Control Laws
 0:24:55
0:24:55
Q Learning In Reinforcement Learning | Q Learning Example | Machine Learning Tutorial | Simplilearn
 0:57:33
0:57:33
MIT 6.S191 (2023): Reinforcement Learning
 0:24:04
0:24:04
Q Learning Intro/Table - Reinforcement Learning p.1
 0:08:56
0:08:56
Introduction to Reinforcement Learning | Scope of Reinforcement Learning by Mahesh Huddar
 0:03:19
0:03:19
Deep Learning Cars
 0:36:26
0:36:26
A friendly introduction to deep reinforcement learning, Q-networks and policy gradients
 0:28:58
0:28:58
Q Learning Algorithm and Agent - Reinforcement Learning p.2
 0:29:13
0:29:13
Q Learning Explained | Reinforcement Learning Using Python | Q Learning in AI | Edureka
 0:15:55
0:15:55
Reinforcement Learning Made Simple - Reward
Комментарии