filmov
tv
Design a High-Throughput Logging System | System Design

Показать описание
Logging systems are commonly found in large systems with multiple moving parts. For these high-throughput real-time systems, there are a number of challenges and considerations at scale. This video gives a high-level introduction to some of these challenges and how to overcome them.
Table of Contents:
0:00 - Introduction
0:27 - Requirements
1:33 - Naive Solution
2:18 - Sharding
3:07 - Bucketing
4:15 - Sharding and Bucketing Combined
5:05 - Migrating to Cold Storage
7:00 - Next Steps
Socials:
 0:08:23
0:08:23
Design a High-Throughput Logging System | System Design
 0:15:00
0:15:00
Distributed Logging System Design | Distributed Logging in Microservices | Systems Design Interview
 0:07:42
0:07:42
design a high throughput logging system system design
 1:19:49
1:19:49
System Design: Logging Service (5+ Approaches)
 0:21:32
0:21:32
Distributed Metrics/Logging Design Deep Dive with Google SWE! | Systems Design Interview Question 14
 0:20:52
0:20:52
27: High Throughput Stock Exchange | Systems Design Interview Questions With Ex-Google SWE
 0:56:52
0:56:52
Scalable and Reliable Logging at Pinterest (DataEngConf SF16)
 0:06:05
0:06:05
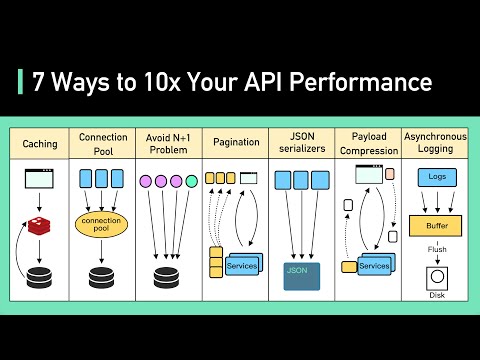
Top 7 Ways to 10x Your API Performance
 0:04:21
0:04:21
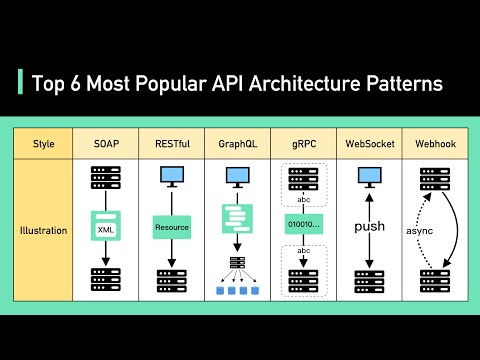
Top 6 Most Popular API Architecture Styles
 0:35:05
0:35:05
High Throughput with Low Resource Usage: A Logging Journey - Eduardo Silva, Calyptia
 0:06:58
0:06:58
How To Choose The Right Database?
 0:05:48
0:05:48
Cache Systems Every Developer Should Know
 0:14:03
0:14:03
SREcon22 Europe/Middle East/Africa - How We Implemented High Throughput Logging at Spotify
 0:34:17
0:34:17
Murron: Reliable Logging Pipeline | Slack
 0:34:42
0:34:42
Adventures in High Performance Logging | Ryan Resella | Code BEAM V
 0:02:35
0:02:35
Kafka in 100 Seconds
 0:05:02
0:05:02
System Design: Why is Kafka fast?
 0:02:28
0:02:28
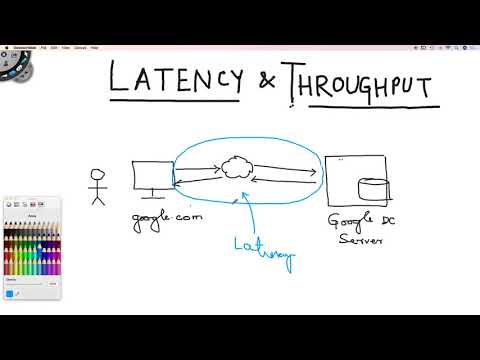
Latency vs Throughput
 0:45:24
0:45:24
Design Instagram System Design Battle with 3 FAANG Staff Engineers
 0:58:32
0:58:32
Automated high-throughput Wannierisation - Giovanni Pizzi
 0:35:48
0:35:48
Fastest Automatic Firewood Processing Machine | Dangerous Big Chainsaw Cutting Tree machines ▶3
 0:41:48
0:41:48
Fluentd and Docker Infrastructure
 0:44:33
0:44:33
SREcon17 Europe/Middle East/Africa - OK Log: Distributed and Coördination-Free Logging
 0:21:47
0:21:47
High-Performance Analytics with Probabilistic Data Structures: the Power of HyperLogLog
Комментарии