filmov
tv
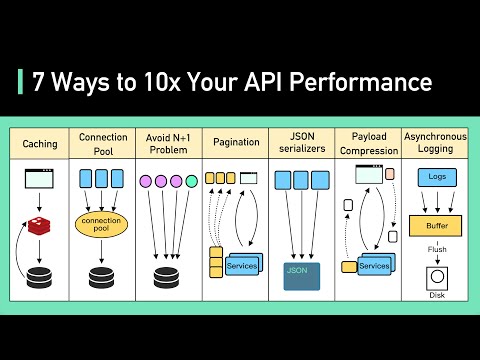
Top 7 Ways to 10x Your API Performance

Показать описание
Animation tools: Adobe Illustrator and After Effects.
Checkout our bestselling System Design Interview books:
ABOUT US:
Covering topics and trends in large-scale system design, from the authors of the best-selling System Design Interview series.
 0:06:05
0:06:05
Top 7 Ways to 10x Your API Performance
 0:07:58
0:07:58
top 7 ways to 10x your api performance
 0:00:52
0:00:52
How to make your desktop look 10X better!
 0:16:45
0:16:45
7 Ways To 10X Your Music On Social Media
 0:09:23
0:09:23
7 Tips To Learn Music Production At Home 10x FASTER!
 0:08:18
0:08:18
7 FREE Ways to Make Your Videos 10X Better | CapCut Editing
 0:00:30
0:00:30
How to Make 10x 🚀🚀🚀Faster Windows use this Secret Method | #howtomakeslowcomputerfast #basic2smart...
 0:00:38
0:00:38
How to make RICE taste 10x BETTER
 1:04:45
1:04:45
J.E.D.I. Training MATH for DIGITAL SAT - Day 6 of 7 (37 Digital SAT Math Problems EXPLAINED)
 1:01:06
1:01:06
7 Ways to Close Like Grant Cardone - 10X Automotive Weekly
 0:00:22
0:00:22
3 Tips to Make Your Outfit 10x BETTER
 0:00:23
0:00:23
Make Your iPhone Battery Last 10X Longer 🤯
 0:16:19
0:16:19
How to triple your memory by using this trick | Ricardo Lieuw On | TEDxHaarlem
 0:06:20
0:06:20
7 Tips to Work 10x Faster in SEO: More Traffic Spending Less Time
 0:02:02
0:02:02
Get 10x BETTER at Gorilla Tag with These Tips
 0:12:58
0:12:58
10 Simple Tips That Will Make Your Hair Grow Faster
 0:10:11
0:10:11
Top 10 BOSS Apps To 10x Your Productivity From Anywhere
 0:04:31
0:04:31
7 EFFECTS to Make Your Videos Look 10x BETTER! DaVinci Resolve 18
 0:00:40
0:00:40
This is 10x Better Than Store Bought Milk
 0:00:24
0:00:24
Nursery Hack to Save a Ton of $
 0:00:38
0:00:38
10X EXTEND THE LIFE OF YOUR SENKO - Wacky Worm Bass Fishing
 0:00:43
0:00:43
These Accessories Make Your Fits 10x’s Better
 0:12:34
0:12:34
15 Amazing Shortcuts You Aren't Using
 0:07:58
0:07:58
How To 10x Your Productivity - Top 6 AI Tools
Комментарии