filmov
tv
3.4 Spark Cache vs Persist | Spark Interview Questions

Показать описание
As part of our spark Interview question Series, we want to help you prepare for your spark interviews. We will discuss various topics about spark like Lineage, reduceby vs group by, yarn client mode vs yarn cluster mode etc.
As part of this video we are covering difference between Spark cache() and persist()
Please subscribe to our channel.
Here is link to other spark interview questions
Here is link to other Hadoop interview questions
As part of this video we are covering difference between Spark cache() and persist()
Please subscribe to our channel.
Here is link to other spark interview questions
Here is link to other Hadoop interview questions
 0:07:20
0:07:20
Cache vs Persist | Spark Tutorial | Deep Dive
 0:00:59
0:00:59
Spark Interview Question : Cache vs Persist
 0:18:56
0:18:56
23. Databricks | Spark | Cache vs Persist | Interview Question | Performance Tuning
 0:03:39
0:03:39
#6 are Cache and Persist the Spark Transformations or Actions English
 0:11:35
0:11:35
What is Cache and Persist in PySpark And Spark-SQL using Databricks? | Databricks Tutorial |
 0:08:08
0:08:08
Cache Vs Persist in Spark with Scala - Part 1 | Spark Interview Questions
 0:00:42
0:00:42
Spark Optimization | Cache and Persist | LearntoSpark
 0:09:42
0:09:42
Cache VS Persist With Spark UI: Spark Interview Questions
 0:06:20
0:06:20
Caching and Persisting Data for Performance in Azure Databricks
 1:05:47
1:05:47
(17) - Spark : Cache vs Persist, Accumulator and Broadcast Variable
 0:32:44
0:32:44
cache and persist in spark | Lec-20
 0:20:06
0:20:06
Persist vs cache in Spark Scala 3
 0:11:28
0:11:28
PySpark | Tutorial-13 | Lazy Evaluation | Cache | Persistence | Bigdata Interview FAQ and Answers
 0:08:06
0:08:06
PySpark | Tutorial-14 | Spark Standalone Mode | Cache Vs Persistence | Bigdata Interview FAQ
 0:10:53
0:10:53
Different persistence (methods) storage levels of Spark | Spark Interview questions
 0:21:00
0:21:00
Our Sample Online Class discussion | Spark Performance Tuning Practical about Cache Persistence
 0:01:00
0:01:00
spark out of memory exception
 0:01:48
0:01:48
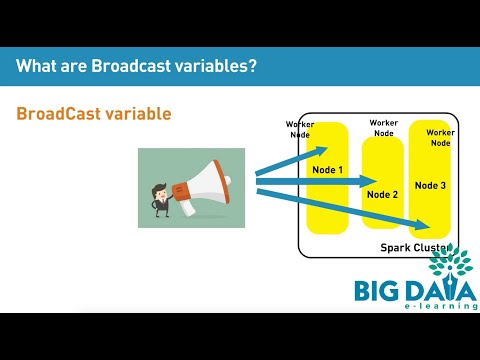
Spark Broadcast variable
 0:10:02
0:10:02
Spark - Repartition Or Coalesce
 0:07:56
0:07:56
Transformations and Caching - Spark Screencast #3
 0:08:32
0:08:32
Spark Executor Core & Memory Explained
 0:14:48
0:14:48
Databricks Tutorial 12 : SQL Cache, spark cache, spark persistence, pyspark persost ,#PySparkCache
 1:03:04
1:03:04
Spark Persist and Cache along with Various Storage Levels
 0:32:23
0:32:23
Apache Spark Repartition,coalsec and Persistence
Комментарии