filmov
tv
Spark Broadcast variable

Показать описание
ATTENTION DATA SCIENCE ASPIRANTS:
Click Below Link to Download Proven 90-Day Roadmap to become a Data Scientist in 90 days
In this video, we will look at what broadcast variables are in spark, how do we create a broadcast variable and finally we will look at why we need a broadcast variable?
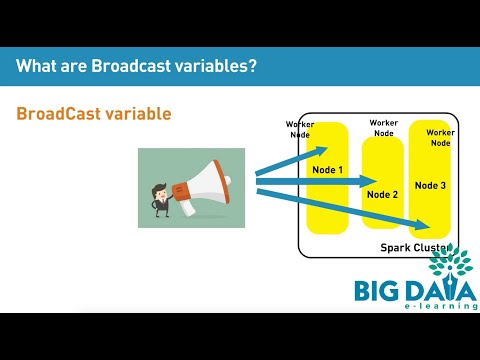
What are Broadcast variables?
Imagine if “Game of thrones” a popular TV show is telecasted only in New York, and anyone in the world who wants to watch the TV show, needs to travel to New York. How ridiculous it would be? How much traffic it would create, because people need to travel to and from different states to NY.
However, that is not the case, as people can watch their favorite shows in their home television, sitting in the comfort of the couch. This is because the TV shows are broadcasted to your home and my home.
This is the same way Broadcast variables work. Broadcast variables are variables that are broadcasted and cached on each machine in the spark cluster, rather than shipping a copy of it with tasks. Spark also uses efficient broadcast algorithms using P2P protocol, to reduce communication costs.
There are some points to note here. Broadcast variables are
1) Read-only,
2) should fit into memory on a single machine,
3) distributed to the cluster.
People familiar with distributed cache in map-reduce paradigm, will find broadcast variables easy to understand as they both are very similar.
How to create Broadcast variables?
Broadcast variables can be created by calling sparkContext dot broadcast method and by passing the RDD in a map format.
Here we are using collect AS map on rdd, which creates a map out of the Rdd. Then we are passing this to spark context dot broadcast method. This creates a broadcast variable.
Why we need Broadcast variables?
Let’s take the below example. Here we have a RDD called productRdd that contains 4 fields cityName, productId, productName, and Price.
We need to join this productRDD with another RDD called zipRdd that contains 2 fields cityName, and zipCode
These 2 rdd needs to be joined based on cityName. If we do a regular join, like below, both the zipRdd data and productRdd will be shuffled across the network causing network overhead.
This can be avoided using broadcast variable, as below.
Here we are creating broadcast variable on top of zipRdd. Then we are using the zipBroadCastVariable to perform join operations.
Here we are applying map transformation on productRdd. For each record in productRdd, we are evaluating if the cityName of productRdd is available in the zipBroadCastVariable.
zipBroadCastVariable dot value gives us the broadcast variable data. Applying get key operation, gives us the value. Remember broadcast variable is nothing but a map.
If cityName of productRdd is available in the zipBroadCastVariable, (which means there is a matching record) we are printing the productRdd values along with the matching zipRdd value.
By performing join operation this way, we are leveraging the broadcast
Click Below Link to Download Proven 90-Day Roadmap to become a Data Scientist in 90 days
In this video, we will look at what broadcast variables are in spark, how do we create a broadcast variable and finally we will look at why we need a broadcast variable?
What are Broadcast variables?
Imagine if “Game of thrones” a popular TV show is telecasted only in New York, and anyone in the world who wants to watch the TV show, needs to travel to New York. How ridiculous it would be? How much traffic it would create, because people need to travel to and from different states to NY.
However, that is not the case, as people can watch their favorite shows in their home television, sitting in the comfort of the couch. This is because the TV shows are broadcasted to your home and my home.
This is the same way Broadcast variables work. Broadcast variables are variables that are broadcasted and cached on each machine in the spark cluster, rather than shipping a copy of it with tasks. Spark also uses efficient broadcast algorithms using P2P protocol, to reduce communication costs.
There are some points to note here. Broadcast variables are
1) Read-only,
2) should fit into memory on a single machine,
3) distributed to the cluster.
People familiar with distributed cache in map-reduce paradigm, will find broadcast variables easy to understand as they both are very similar.
How to create Broadcast variables?
Broadcast variables can be created by calling sparkContext dot broadcast method and by passing the RDD in a map format.
Here we are using collect AS map on rdd, which creates a map out of the Rdd. Then we are passing this to spark context dot broadcast method. This creates a broadcast variable.
Why we need Broadcast variables?
Let’s take the below example. Here we have a RDD called productRdd that contains 4 fields cityName, productId, productName, and Price.
We need to join this productRDD with another RDD called zipRdd that contains 2 fields cityName, and zipCode
These 2 rdd needs to be joined based on cityName. If we do a regular join, like below, both the zipRdd data and productRdd will be shuffled across the network causing network overhead.
This can be avoided using broadcast variable, as below.
Here we are creating broadcast variable on top of zipRdd. Then we are using the zipBroadCastVariable to perform join operations.
Here we are applying map transformation on productRdd. For each record in productRdd, we are evaluating if the cityName of productRdd is available in the zipBroadCastVariable.
zipBroadCastVariable dot value gives us the broadcast variable data. Applying get key operation, gives us the value. Remember broadcast variable is nothing but a map.
If cityName of productRdd is available in the zipBroadCastVariable, (which means there is a matching record) we are printing the productRdd values along with the matching zipRdd value.
By performing join operation this way, we are leveraging the broadcast
 0:13:33
0:13:33
 0:01:48
0:01:48
 0:08:02
0:08:02
 0:07:39
0:07:39
 0:03:58
0:03:58
 0:00:59
0:00:59
 0:12:35
0:12:35
 0:18:18
0:18:18
 0:05:38
0:05:38
 0:02:11
0:02:11
 0:07:58
0:07:58
 0:00:41
0:00:41
 0:11:56
0:11:56
 0:04:53
0:04:53
 0:04:00
0:04:00
 0:15:04
0:15:04
 0:03:43
0:03:43
 0:16:09
0:16:09
 0:17:03
0:17:03
 0:07:46
0:07:46
 0:11:08
0:11:08
 0:12:29
0:12:29
 0:08:08
0:08:08
 0:04:52
0:04:52