filmov
tv
RAG From Scratch: Part 2 (Indexing)
Показать описание
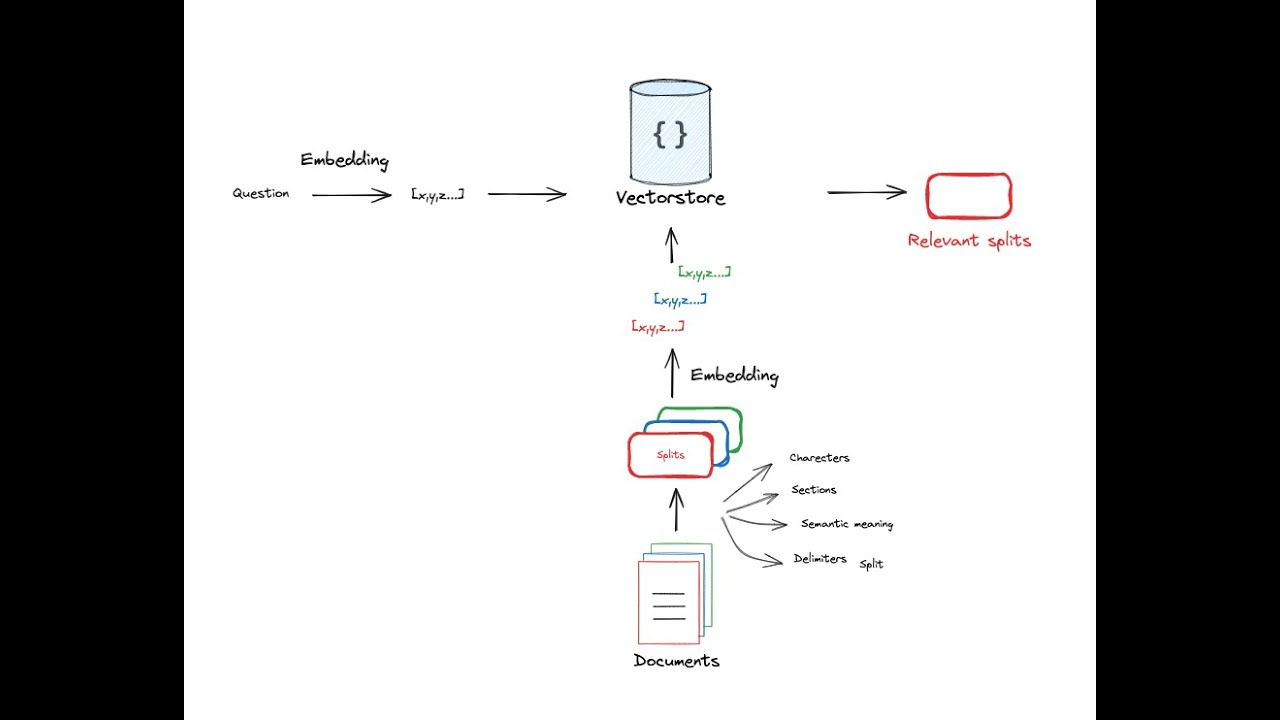
This is the second video in our series on RAG. The aim of this series is to build up an understanding of RAG from scratch, starting with the basics of indexing, retrieval, and generation. This video focuses on indexing, covering the process of document loading, splitting, and embedding.
Code:
Slides:
Code:
Slides:
 0:04:52
0:04:52
RAG From Scratch: Part 2 (Indexing)
 5:40:59
5:40:59
Local Retrieval Augmented Generation (RAG) from Scratch (step by step tutorial)
 0:06:09
0:06:09
RAG from scratch: Part 5 (Query Translation -- Multi Query)
 0:06:59
0:06:59
RAG from scratch: Part 8 (Query Translation -- Step Back)
 0:04:47
0:04:47
RAG from scratch: Part 9 (Query Translation -- HyDE)
 0:05:59
0:05:59
RAG from scratch: Part 11 (Query Structuring)
 0:05:42
0:05:42
RAG from scratch: Part 6 (Query Translation -- RAG Fusion)
 0:26:00
0:26:00
Building Corrective RAG from scratch with open-source, local LLMs
 0:15:30
0:15:30
How I created Retrieval-Augmented Generation (RAG) using locally run LLM | Tools & Techniques - ...
 0:06:37
0:06:37
RAG from scratch: Part 7 (Query Translation -- Decomposition)
 2:33:11
2:33:11
Learn RAG From Scratch – Python AI Tutorial from a LangChain Engineer
 0:06:35
0:06:35
RAG from scratch: Part 12 (Multi-Representation Indexing)
 0:06:36
0:06:36
What is Retrieval-Augmented Generation (RAG)?
 0:21:33
0:21:33
Python RAG Tutorial (with Local LLMs): AI For Your PDFs
 0:37:02
0:37:02
End to End RAG Pipeline Part-2 | Advance Reterival Process | RAG Architecture In depth
 0:16:42
0:16:42
RAG + Langchain Python Project: Easy AI/Chat For Your Docs
 0:07:13
0:07:13
RAG From Scratch: Part 14 (ColBERT)
 0:50:58
0:50:58
I'm So Tired Of Dealing With My Ex-Husband. Grow A Clean Vegetable Garden
 0:07:40
0:07:40
RAG From Scratch: Part 13 (RAPTOR)
 0:24:05
0:24:05
Keep practicing Scott Joplin's Gladiolus Rag until it goes okay | plog #2
 0:04:43
0:04:43
NEWEST Clay Products | Ultra Clay Line By The Rag Company
 0:41:05
0:41:05
How to play 'Cannonball Rag' - Comping and Melody (Part 2)
 0:00:44
0:00:44
The 2021 NS RAG+2 - all round drop bar bike
 0:18:35
0:18:35
Building Production-Ready RAG Applications: Jerry Liu
Комментарии