filmov
tv
Text Classification - Natural Language Processing With Python and NLTK p.11

Показать описание
Now that we understand some of the basics of of natural language processing with the Python NLTK module, we're ready to try out text classification. This is where we attempt to identify a body of text with some sort of label.
To start, we're going to use some sort of binary label. Examples of this could be identifying text as spam or not, or, like what we'll be doing, positive sentiment or negative sentiment.
To start, we're going to use some sort of binary label. Examples of this could be identifying text as spam or not, or, like what we'll be doing, positive sentiment or negative sentiment.
 0:11:41
0:11:41
Text Classification - Natural Language Processing With Python and NLTK p.11
 0:03:03
0:03:03
Text Classification Explained | Sentiment Analysis Example | Deep Learning Applications | Edureka
 0:03:41
0:03:41
Natural Language Processing: Mastering Text Classification with NLP- Comprehensive Beginner's G...
 0:20:59
0:20:59
fastText tutorial | Text Classification Using fastText | NLP Tutorial For Beginners - S2 E13
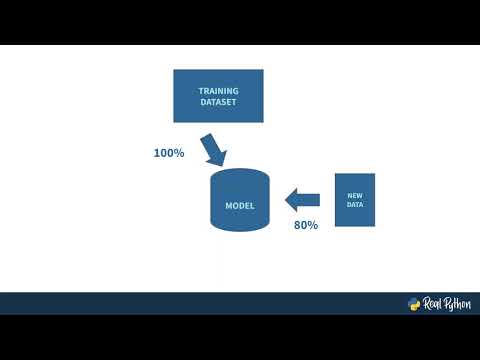 0:13:16
0:13:16
Natural Language Processing (NLP) and Text Classification With Python
 4:07:05
4:07:05
Natural Language Processing: Text classification | Data Science Summer School
 0:05:56
0:05:56
Using AutoML Natural Language for custom text classification
 0:14:31
0:14:31
NLP - Text Preprocessing and Text Classification (using Python)
 0:04:14
0:04:14
What is Generative AI | Most Demanding Skills in 2024| Logicmojo Data Science
 0:29:18
0:29:18
Text Classification with Python: Build and Compare Three Text Classifiers
 0:04:33
0:04:33
Text Classification with Word Embeddings
 3:02:33
3:02:33
Natural Language Processing with spaCy & Python - Course for Beginners
 0:04:15
0:04:15
Text Classification with Python | Natural Language Processing Course Part 5| Scikit Learn / sklearn
 2:16:49
2:16:49
Natural Language Processing from Scratch - Bag of Words Model for Text Classification
 0:16:28
0:16:28
8. Text Classification Using Convolutional Neural Networks
 0:23:17
0:23:17
TensorFlow Tutorial 11 - Text Classification - NLP Tutorial
 1:37:46
1:37:46
Complete Natural Language Processing (NLP) Tutorial in Python! (with examples)
 0:20:15
0:20:15
Text Classification Using Naive Bayes | Naive Bayes Algorithm In Machine Learning | Simplilearn
 0:38:47
0:38:47
Text Classification With Python
 0:11:41
0:11:41
Text Classification Natural Language Processing With Python and NLTK p 11
 0:23:15
0:23:15
Natural Language Processing Explained for Beginners-Text Classification using NLP
 0:18:23
0:18:23
Natural Language Processing(Text Classification)
 0:14:54
0:14:54
Natural Language Processing Text Classification
 0:52:11
0:52:11
Text Classification | NLP Lecture 6 | End to End | Average Word2Vec
Комментарии