filmov
tv
236 - Pre-training U-net using autoencoders - Part 2 - Generating encoder weights for U-net

Показать описание
Code generated in the video can be downloaded from here:
The video walks you through the process of training an autoencoder model and using the encoder weights for U-net.
The video walks you through the process of training an autoencoder model and using the encoder weights for U-net.
 0:32:31
0:32:31
236 - Pre-training U-net using autoencoders - Part 2 - Generating encoder weights for U-net
 0:28:20
0:28:20
235 - Pre-training U-net using autoencoders - Part 1 - Autoencoders and visualizing features
 0:03:02
0:03:02
Tracking by clustering using U-NET CNN and more global descriptors
 0:13:48
0:13:48
Test segmentation unet(resnet50 encoder) 1344x704 window, 672x352 net input
 0:00:19
0:00:19
stop using loofah❌ instead use this✅ #skincare #haircare#loofah #viral #shorts #youtubeshorts
 0:09:08
0:09:08
227 - Various U-Net models using keras unet collection library - for semantic image segmentation
 0:00:30
0:00:30
Terrible Emergency Landing Of A380, But B747 Pilot Made Quick Decision To Abort Takeoff on Time
 0:00:12
0:00:12
😨 'I'm Prepared To Die' | Israel Adesanya Before 5th Round vs Kelvin Gastelum
 0:00:59
0:00:59
Mode Collapse in GANs
 0:00:14
0:00:14
LOOSE SKIN AFTER VSG SURGERY #vsg #weightloss
 0:16:05
0:16:05
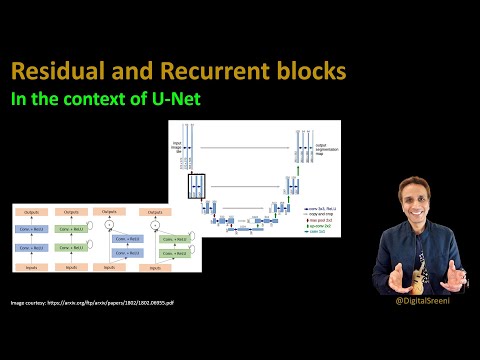
224 - Recurrent and Residual U-net
 0:00:19
0:00:19
#encantadia #edit #amihan #trending #sangre #alena #trending #danaya #pirena
 0:00:15
0:00:15
Jealous Sarada😇 #sarada #boruto
 0:00:15
0:00:15
Our New Refrigerator | Samsung 324 L Frost Free Double Door 2023 Model | 5 in 1 Convertible | Latest
 0:22:02
0:22:02
EASIEST Way to Fine-Tune a LLM and Use It With Ollama
 0:05:04
0:05:04
u net teaser
 0:00:11
0:00:11
IIT Bombay CSE 😍 #shorts #iit #iitbombay
 0:00:16
0:00:16
Radha ji dance practice with Dance choreographer🥰🥰#short #video
 0:00:23
0:00:23
Rich poor and Middle class sign #life #astrology #fame #marriage #respect #YousafPalmist#alphabet
 0:00:23
0:00:23
Why kids want cereal #shorts
 0:00:34
0:00:34
Case DISMISSED in 34 SECONDS!
 0:00:23
0:00:23
The Moment gojo vs sukuna fight.. begins [JJK/ANIME MANGA] #edit #gojo #sukuna
 0:00:06
0:00:06
#shorts #viral #shortsvideo #ytshorts #kidsschoolproject /kids school project work/subtraction
 0:00:36
0:00:36
236. This PowerPoint design is so nice 😍 #powerpoint #presentation #tutorial #ppt
Комментарии