filmov
tv
Speech Recognition in Python | finetune wav2vec2 model for a custom ASR model
Показать описание
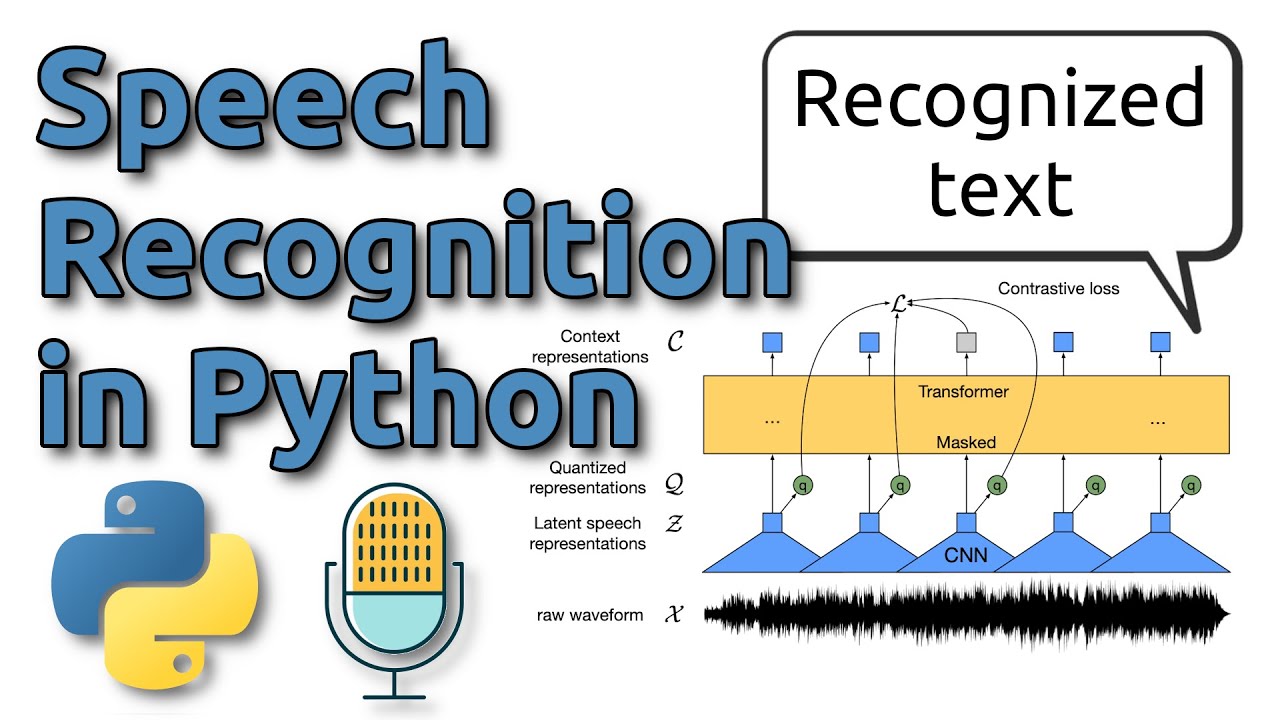
In this YouTube tutorial, we'll explore the Wav2Vec2 model, a powerful tool for speech recognition and representation learning. If you're in the field of speech recognition or interested in top-notch models, you've likely heard of Wav2Vec2. This video focuses on practical steps, guiding you through fine-tuning Wav2Vec2 with your own speech data without delving deep into technicalities.
Wav2Vec2 is designed for Connectionist Temporal Classification (CTC) loss, and we'll show you how to use it effectively for your tasks. You can leverage pre-trained models and adapt them to your needs, saving you from starting from scratch.
We'll walk you through the code, ensuring you have the necessary requirements like PyTorch and Transformers. You'll also learn how to apply audio augmentations to enhance data quality.
Throughout the tutorial, you'll discover how to monitor your model's progress with TensorBoard, implement early stopping, and save the best checkpoints. We'll also cover converting your PyTorch model to ONNX for easier deployment on various platforms.
To validate the model's performance, we'll run inference on a test dataset, checking character and word error rates to showcase the model's accuracy.
This tutorial aims to empower you to use Wav2Vec2 effectively for speech recognition tasks, whether you're a beginner or an experienced practitioner.
#transformers #nlp #wav2vec #tensorflow #pytorch
Wav2Vec2 is designed for Connectionist Temporal Classification (CTC) loss, and we'll show you how to use it effectively for your tasks. You can leverage pre-trained models and adapt them to your needs, saving you from starting from scratch.
We'll walk you through the code, ensuring you have the necessary requirements like PyTorch and Transformers. You'll also learn how to apply audio augmentations to enhance data quality.
Throughout the tutorial, you'll discover how to monitor your model's progress with TensorBoard, implement early stopping, and save the best checkpoints. We'll also cover converting your PyTorch model to ONNX for easier deployment on various platforms.
To validate the model's performance, we'll run inference on a test dataset, checking character and word error rates to showcase the model's accuracy.
This tutorial aims to empower you to use Wav2Vec2 effectively for speech recognition tasks, whether you're a beginner or an experienced practitioner.
#transformers #nlp #wav2vec #tensorflow #pytorch
 0:07:32
0:07:32
Speech Recognition in Python
 1:59:40
1:59:40
Python Speech Recognition Tutorial – Full Course for Beginners
 0:08:38
0:08:38
Creating a Speech to Text Program with Python
 0:05:47
0:05:47
Speech recognition in Python made easy | Python Tutorial
 0:06:52
0:06:52
Easy Speech Recognition - Using Python
 0:27:13
0:27:13
Speech Recognition Using Python | How Speech Recognition Works In Python | Simplilearn
 0:05:57
0:05:57
Speech Recognition using Python
 0:30:08
0:30:08
Python Speech Recognition Tutorial | Speech to Text in Python | Speech to Text Converter|Simplilearn
![🔴 [LIVE] Kuliah](https://i.ytimg.com/vi/rW367qkk3ac/hqdefault.jpg) 1:44:14
1:44:14
🔴 [LIVE] Kuliah Kecerdasan buatan Day 2 - Speech Emote Recognition (MFCC)
 0:08:41
0:08:41
SUPER Fast AI Real Time Speech to Text Transcribtion - Faster Whisper / Python
 0:16:32
0:16:32
I Built a Personal Speech Recognition System for my AI Assistant
 0:21:22
0:21:22
Python Speech Recognition, Voice recognition | Python
 0:12:20
0:12:20
How to use #Vosk -- the Offline Speech Recognition Library for Python
 0:04:59
0:04:59
OpenAI Whisper Demo: Convert Speech to Text in Python
 0:19:52
0:19:52
Audio Data Processing in Python
 0:19:21
0:19:21
Build your own real-time voice command recognition model with TensorFlow
 0:26:18
0:26:18
Speech Recognition in Python | finetune wav2vec2 model for a custom ASR model
 0:22:32
0:22:32
Speech Recognition Using Python | Speech To Text Translation in Python | Python Training | Edureka
 0:20:19
0:20:19
Voice Assistant with Wake Word in Python
 0:08:50
0:08:50
Python Tutorial - Speech Recognition (Personal Assistant)
 0:06:24
0:06:24
How Does Speech Recognition Work? Learn about Speech to Text, Voice Recognition and Speech Synthesis
 0:07:43
0:07:43
Getting Started with Speech Recognition in Python + Speaker Detection
 0:15:56
0:15:56
Make a Voice Assistant with Python
 0:34:26
0:34:26
Real-Time Speech Recognition With Your Microphone [Beginner Tutorial With Full Code]
Комментарии