filmov
tv
Real-time target sound extraction using attention
Показать описание
Real-time target sound extraction, ICASSP 2023
Bandhav Veluri, University of Washington
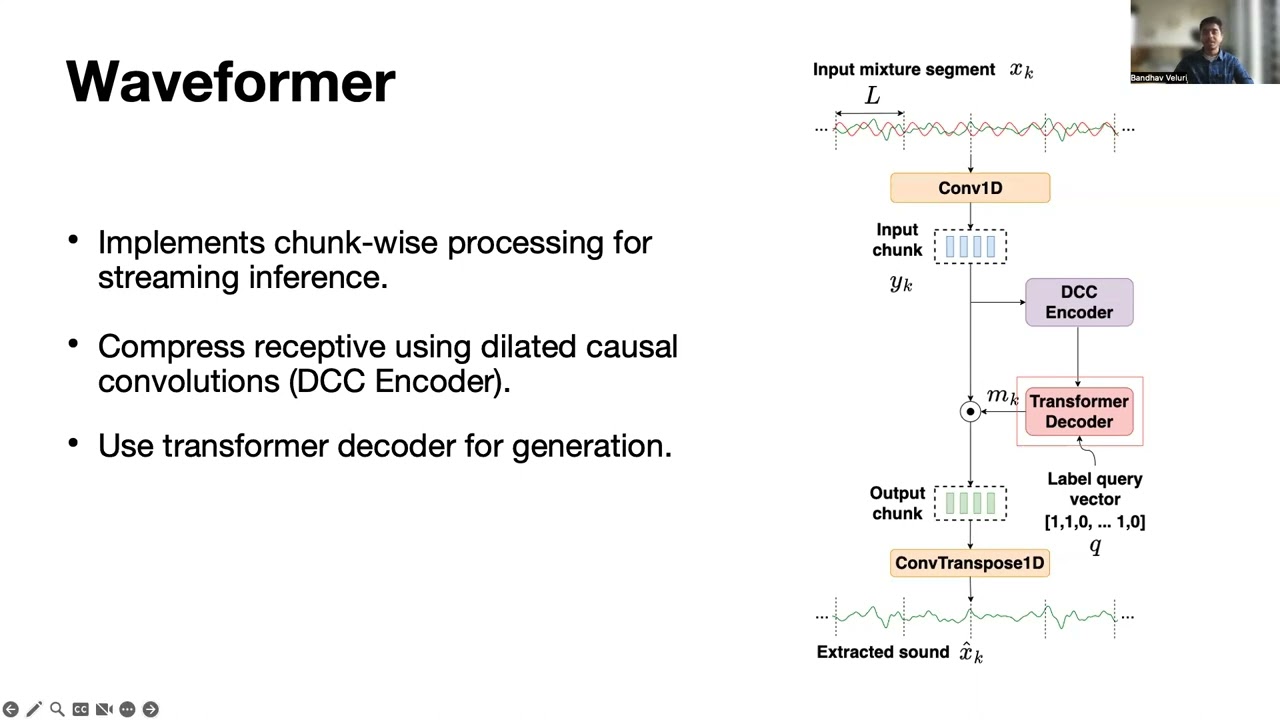
We present the first neural network model to achieve real-time and streaming target sound extraction. To accomplish this, we propose Waveformer, an encoder-decoder architecture with a stack of dilated causal convolution layers as the encoder, and a transformer decoder layer as the decoder. This hybrid architecture uses dilated causal convolutions for processing large receptive fields in a computationally efficient manner while also leveraging the generalization performance of transformer-based architectures.
This video is closed captioned.
Bandhav Veluri, University of Washington
We present the first neural network model to achieve real-time and streaming target sound extraction. To accomplish this, we propose Waveformer, an encoder-decoder architecture with a stack of dilated causal convolution layers as the encoder, and a transformer decoder layer as the decoder. This hybrid architecture uses dilated causal convolutions for processing large receptive fields in a computationally efficient manner while also leveraging the generalization performance of transformer-based architectures.
This video is closed captioned.
 0:06:15
0:06:15
 0:15:44
0:15:44
 0:03:16
0:03:16
 0:53:18
0:53:18
 3:00:29
3:00:29
 0:03:34
0:03:34
 0:31:03
0:31:03
 0:10:05
0:10:05
 0:00:36
0:00:36
 0:00:34
0:00:34
 0:00:29
0:00:29
 0:34:26
0:34:26
 0:00:24
0:00:24
 0:00:30
0:00:30
 0:00:14
0:00:14
 0:00:16
0:00:16
 0:00:12
0:00:12
 0:00:16
0:00:16
 0:01:01
0:01:01
 0:00:35
0:00:35
 0:00:24
0:00:24
 0:00:40
0:00:40
 0:00:16
0:00:16
 0:41:39
0:41:39