filmov
tv
Handling Skewed Data | Tips on running Spark in Production | Course on Apache Spark Core | Lesson 25

Показать описание
Full Course is available here:
 0:18:31
0:18:31
Handling Skewed Data | Tips on running Spark in Production | Course on Apache Spark Core | Lesson 25
 0:11:36
0:11:36
Correcting Skewed Data with Scipy and Numpy
 0:06:09
0:06:09
Salting Technique to Handle Skewed data in Apache Spark
 0:07:12
0:07:12
How to Deal with Skewed Data
 0:07:15
0:07:15
Are You Falling For The Traps Of Skewed Data In Customer Service?
 0:10:22
0:10:22
Skewness - Right, Left & Symmetric Distribution - Mean, Median, & Mode With Boxplots - Stati...
 0:06:21
0:06:21
How to describe shape of statistical distribution (positive skew, negatively skewed, symmetrical)
 0:06:01
0:06:01
skewed data / positively skewed vs negatively skewed data
 0:06:05
0:06:05
Median, mean and skew from density curves | AP Statistics | Khan Academy
 0:06:51
0:06:51
Statistics-Left Skewed And Right Skewed Distribution And Relation With Mean, Median And Mode
 0:04:47
0:04:47
Right skewed histogram, Left skewed histogram explained, Skewed histogram examples
 0:16:32
0:16:32
Skewed Data & Outliers
 0:18:07
0:18:07
Skewness in R - How to Deal with Skewed Data!
 0:04:06
0:04:06
Symmetry and Skewness (1.8)
 0:35:19
0:35:19
(IS04) Skewed-Data Analysis
 0:01:41
0:01:41
Right Skewed vs. Left Skewed
 0:17:38
0:17:38
Spark Skewed Data Problem: How to Fix it Like a Pro
 0:09:15
0:09:15
How to Create Skewed Bell Curve in Excel
 0:29:43
0:29:43
Working with Skewed Data: The Iterative Broadcast - Rob Keevil & Fokko Driesprong
 0:00:11
0:00:11
data distribution|mean|median|skewness|Negatively Skewed distribution#shorts #statistics#datascience
 0:05:07
0:05:07
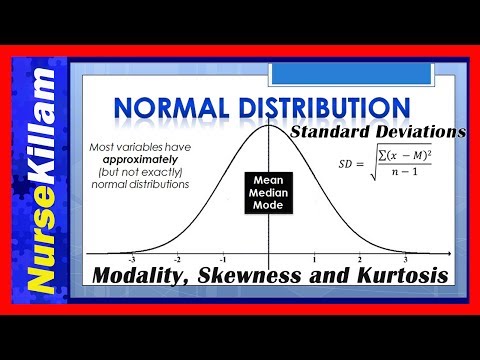
Normal Distributions, Standard Deviations, Modality, Skewness and Kurtosis: Understanding concepts
 0:07:31
0:07:31
Station Help - #5 - Skewed Data
 0:06:02
0:06:02
Skewness And Kurtosis And Moments | What Is Skewness And Kurtosis? | Statistics | Simplilearn
 0:09:29
0:09:29
Reflection of Negative skewed Data in SPSS
Комментарии