filmov
tv
Deploying Serverless Inference Endpoints

Показать описание
VIDEO RESOURCES:
OTHER TRELIS LINKS:
TIMESTAMPS:
0:00 Deploying a Serverless API Endpoint
0:17 Serverless Demo
1:19 Video Overview
1:44 Serverless Use Cases
3:31 Setting up a Serverless API
13:31 Inferencing a Serverless Endpoint
17:55 Serverless Costs versus GPU Rental
20:02 Accessing Instructions and Scripts
 0:20:18
0:20:18
Deploying Serverless Inference Endpoints
 0:06:33
0:06:33
How I deploy serverless containers for free
 0:22:13
0:22:13
Introduction to Amazon SageMaker Serverless Inference | Concepts & Code examples
 0:25:16
0:25:16
AWS re:Invent 2021 - Serverless Inference on SageMaker! FOR REAL!
 0:03:48
0:03:48
Serverless was a big mistake... says Amazon
 0:19:28
0:19:28
AWS On Air ft. Amazon Sagemaker Serverless Inference
 0:19:53
0:19:53
AWS On Air ft. Amazon SageMaker Serverless Inference | AWS Events
 0:37:22
0:37:22
AWS re:Invent 2021 - {New Launch} Amazon SageMaker serverless inference (Preview)
 0:54:07
0:54:07
AWS re:Invent 2022 - Deploy ML models for inference at high performance & low cost, ft AT&T ...
 0:14:13
0:14:13
Deploy LLMs using Serverless vLLM on RunPod in 5 Minutes
 0:51:11
0:51:11
AWS Summit DC 2022 - Amazon SageMaker Inference explained: Which style is right for you?
 0:22:32
0:22:32
#3-Deployment Of Huggingface OpenSource LLM Models In AWS Sagemakers With Endpoints
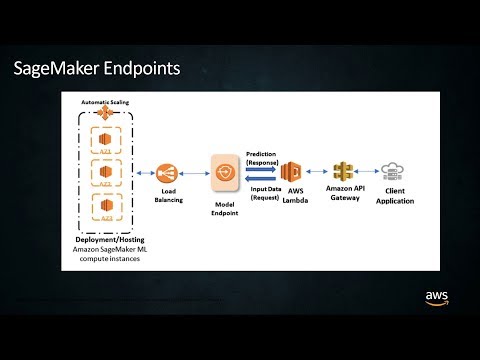 0:07:53
0:07:53
Deploy Your ML Models to Production at Scale with Amazon SageMaker
 0:02:00
0:02:00
Amazon SageMaker ML Inference | Amazon Web Services
 0:22:20
0:22:20
AWS On Air San Fran Summit 2022 ft. Amazon SageMaker Serverless Inference
 0:46:46
0:46:46
Hugging Face Inference Endpoints live launch event recorded on 9/27/22
 0:17:14
0:17:14
AWS re:Invent 2020: How CATCH FASHION built a serverless ML inference service with AWS Lambda
 0:09:39
0:09:39
Serverless ML Inference at Scale with Rust, ONNX Models on AWS Lambda + EFS
 0:32:49
0:32:49
AWS re:Invent 2020: Deploying PyTorch models for inference using TorchServe
 0:21:44
0:21:44
How to build ML Architecture with AWS SageMaker + Lambda + API Gateway | HANDS-ON TUTORIAL
 0:05:17
0:05:17
Microservices Explained in 5 Minutes
 0:20:12
0:20:12
🆕 HTTPS endpoints for your AWS Lambda functions with Function URLs
 0:08:19
0:08:19
How to serve your ComfyUI model behind an API endpoint
 0:12:41
0:12:41
Deploy ML model in 10 minutes. Explained
Комментарии