filmov
tv
Realtime Socket Streaming with Apache Spark | End to End Data Engineering Project
Показать описание
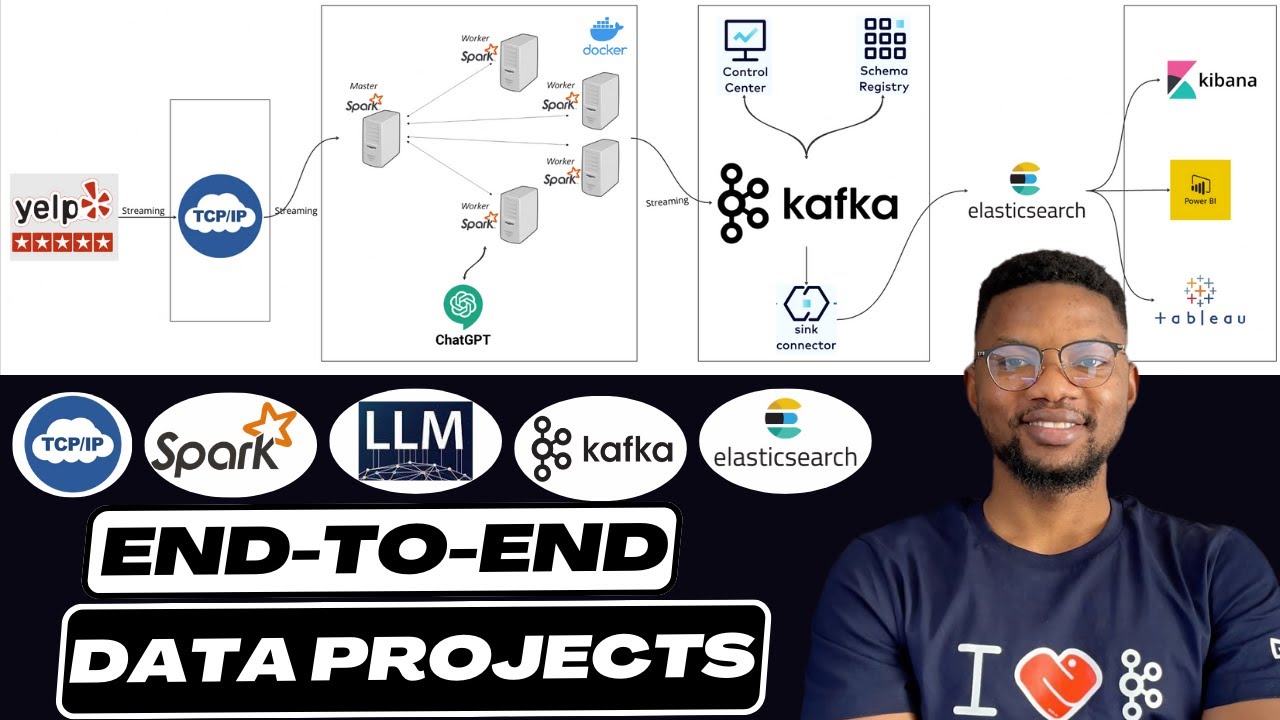
In this video, you will be building a real-time data streaming pipeline with a dataset of 7 million records. We'll utilize a powerful stack of tools and technologies, including TCP/IP Socket, Apache Spark, OpenAI Large Language Model (LLM), Kafka, and Elasticsearch.
📚 What You'll Learn:
👉 Setting up and configuring TCP/IP for data transmission over Socket.
👉 Streaming Data With Apache Spark from Socket
👉 Realtime Sentiment Analysis with OpenAI LLM (ChatGPT)
👉 Prompt Engineering
👉 Setting up Kafka for real-time data ingestion and distribution.
👉 Using Elasticsearch for efficient data indexing and search capabilities.
✨ Timestamps: ✨
0:00 Introduction
01:10 Creating Spark Master-worker architecture with Docker
10:40 Setting up the TCP IP Socket Source Stream
23:25 Setting up Apache Spark Stream
42:56 Setting up Kafka Cluster on confluent cloud
47:12 Getting Keys for Kafka cluster and Schema Registry
1:12:53 Realtime Sentiment Analysis with OpenAI LLM (ChatGPT)
1:24:10 Setting up Elasticsearch deployment on Elastic cloud
1:30:50 Realtime Data Indexing on Elasticsearch
1:36:05 Testing and Results
1:41:50 Outro
🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟
🔗 Useful Links and Resources:
✨ Tags ✨
Data Engineering, Apache Airflow, Kafka, Apache Spark, Cassandra, PostgreSQL, Zookeeper, Docker, Docker Compose, ETL Pipeline, Data Pipeline, Big Data, Streaming Data, Real-time Analytics, Kafka Connect, Spark Master, Spark Worker, Schema Registry, Control Center, Data Streaming, Real-time Data Streaming, OpenAI LLM, Elasticsearch, Data Processing, Data Analytics, TCP/IP, Streaming Solutions, Data Ingestion, Real-time Analysis, Spark Configuration, OpenAI Integration, Kafka Topics, Elasticsearch Indexing, Data Storage, Stream Processing, Machine Learning Integration
✨ Hashtags ✨
#confluent #DataEngineering #TCP #TCPIP #sockets #socketstreaming #Kafka #ApacheSpark #Docker #ETLPipeline #DataPipeline #DataStreaming #OpenAI #Elasticsearch #RealTimeData #BigData #TechTutorial #StreamingAnalytics #MachineLearning #DataFlow #SparkStreaming #DataScience #AIIntegration #RealTimeAnalytics #StreamingData #realtimestreaming #realtime
📚 What You'll Learn:
👉 Setting up and configuring TCP/IP for data transmission over Socket.
👉 Streaming Data With Apache Spark from Socket
👉 Realtime Sentiment Analysis with OpenAI LLM (ChatGPT)
👉 Prompt Engineering
👉 Setting up Kafka for real-time data ingestion and distribution.
👉 Using Elasticsearch for efficient data indexing and search capabilities.
✨ Timestamps: ✨
0:00 Introduction
01:10 Creating Spark Master-worker architecture with Docker
10:40 Setting up the TCP IP Socket Source Stream
23:25 Setting up Apache Spark Stream
42:56 Setting up Kafka Cluster on confluent cloud
47:12 Getting Keys for Kafka cluster and Schema Registry
1:12:53 Realtime Sentiment Analysis with OpenAI LLM (ChatGPT)
1:24:10 Setting up Elasticsearch deployment on Elastic cloud
1:30:50 Realtime Data Indexing on Elasticsearch
1:36:05 Testing and Results
1:41:50 Outro
🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟
🔗 Useful Links and Resources:
✨ Tags ✨
Data Engineering, Apache Airflow, Kafka, Apache Spark, Cassandra, PostgreSQL, Zookeeper, Docker, Docker Compose, ETL Pipeline, Data Pipeline, Big Data, Streaming Data, Real-time Analytics, Kafka Connect, Spark Master, Spark Worker, Schema Registry, Control Center, Data Streaming, Real-time Data Streaming, OpenAI LLM, Elasticsearch, Data Processing, Data Analytics, TCP/IP, Streaming Solutions, Data Ingestion, Real-time Analysis, Spark Configuration, OpenAI Integration, Kafka Topics, Elasticsearch Indexing, Data Storage, Stream Processing, Machine Learning Integration
✨ Hashtags ✨
#confluent #DataEngineering #TCP #TCPIP #sockets #socketstreaming #Kafka #ApacheSpark #Docker #ETLPipeline #DataPipeline #DataStreaming #OpenAI #Elasticsearch #RealTimeData #BigData #TechTutorial #StreamingAnalytics #MachineLearning #DataFlow #SparkStreaming #DataScience #AIIntegration #RealTimeAnalytics #StreamingData #realtimestreaming #realtime
 1:42:25
1:42:25
Realtime Socket Streaming with Apache Spark | End to End Data Engineering Project
 0:04:57
0:04:57
Apache Flink-47 Flink Source Connector TCP Socket Source Connector
 0:02:18
0:02:18
Live Dashboard Using Apache Kafka and Spring WebSocket
 0:05:28
0:05:28
How Web Sockets work | System Design Interview Basics
 0:06:46
0:06:46
Don't Use Websockets (Until You Try This…)
 0:18:45
0:18:45
Building our first Spark Streaming Application! | PySpark Tutorial
 2:26:31
2:26:31
Build a multiplayer real-time game with WebSockets and Apache Pulsar
 0:02:35
0:02:35
Kafka in 100 Seconds
 0:38:52
0:38:52
Window-based Stream Data Analytics with Spark and Kafka: Apache Spark Streaming
 0:04:21
0:04:21
Top 6 Most Popular API Architecture Styles
 0:06:37
0:06:37
TCP Socket Server Streaming data generator for Apache Spark Network Streaming Test
 0:04:27
0:04:27
How to Make 2500 HTTP Requests in 2 Seconds with Async & Await
 0:48:45
0:48:45
Build Real-Time Streaming ETL Pipelines with Akka Streams, Alpakka and Apache Kafka
 0:02:31
0:02:31
RabbitMQ in 100 Seconds
 0:39:11
0:39:11
Application Data Streaming with Apache Kafka and Swim
 0:17:41
0:17:41
Creating Stream processing application using Spark and Kafka in Scala | Spark Streaming Course
 0:07:17
0:07:17
Display Real Time Updates Using Python, Flask and Websocket
 0:05:47
0:05:47
Swiftchat full demo | Socket.io | Apache Kafka | Redis
 0:12:09
0:12:09
How I like to setup websockets in my web applications
 0:15:26
0:15:26
NodeJS Streams
 0:00:39
0:00:39
Spring WebSocket integration with Apache Kafka
 0:03:01
0:03:01
The different Streams Processing
 0:11:00
0:11:00
Apache Spark Streaming | Real-time data processing for Hadoop | Big Data Tutorial
 0:08:08
0:08:08
Spark Tutorial | Spark Streaming Intro | DStream vs RDD | Apache PySpark for Beginners | Part - 7
Комментарии