filmov
tv
Stanford CS25: V4 I Demystifying Mixtral of Experts
Показать описание
April 25, 2024
Speaker: Albert Jiang, Mistral AI / University of Cambridge
Demystifying Mixtral of Experts
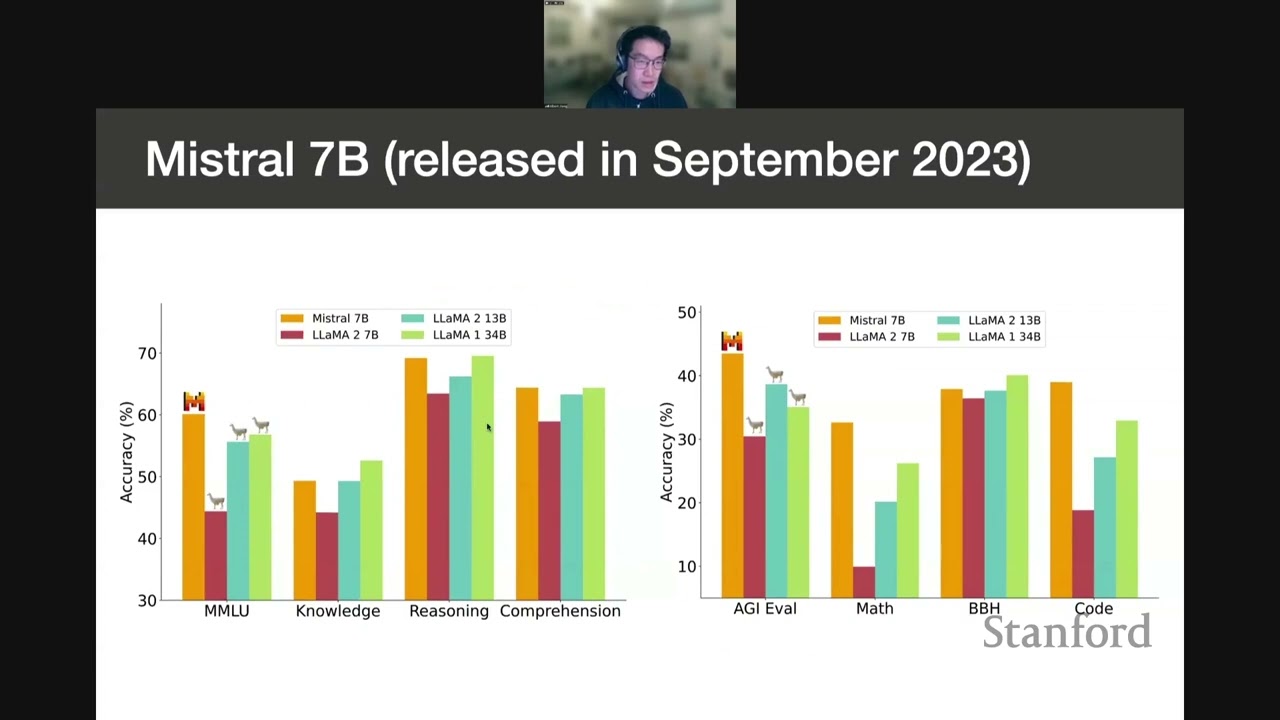
In this talk I will introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combines their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. I will go into the architectural details and analyse the expert routing decisions made by the model.
About the speaker:
Albert Jiang is an AI scientist at Mistral AI, and a final-year PhD student at the computer science department of Cambridge University. He works on language model pretraining and reasoning at Mistral AI, and language models for mathematics at Cambridge.
Speaker: Albert Jiang, Mistral AI / University of Cambridge
Demystifying Mixtral of Experts
In this talk I will introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combines their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. I will go into the architectural details and analyse the expert routing decisions made by the model.
About the speaker:
Albert Jiang is an AI scientist at Mistral AI, and a final-year PhD student at the computer science department of Cambridge University. He works on language model pretraining and reasoning at Mistral AI, and language models for mathematics at Cambridge.
 1:04:32
1:04:32
Stanford CS25: V4 I Demystifying Mixtral of Experts
 0:22:44
0:22:44
Stanford CS25: V1 I Transformers United: DL Models that have revolutionized NLP, CV, RL
 1:05:44
1:05:44
Stanford CS25: V1 I Mixture of Experts (MoE) paradigm and the Switch Transformer
 1:08:37
1:08:37
Stanford CS25: V1 I Transformers in Vision: Tackling problems in Computer Vision
 0:03:13
0:03:13
What is mechanistic interpretability? Neel Nanda explains.
 1:50:11
1:50:11
Textbooks Are All You Need
 0:03:38
0:03:38
George Hotz - GPT-4's real architecture is a 220B parameter mixture model with 8 sets of weight...
 0:57:04
0:57:04
How Witty Works leverages Hugging Face to scale inclusive language
 0:09:08
0:09:08
Transformer Series: Part-1 Basic Introduction (Dr. Aditya Nigam)
 0:18:03
0:18:03
1L Attention - Theory [rough early thoughts]
 0:59:17
0:59:17
Formalizing Explanations of Neural Network Behaviors
 0:47:54
0:47:54
Create ChatGPT From Scratch in 40 Minute
 0:55:27
0:55:27
Open Problems in Mechanistic Interpretability: A Whirlwind Tour
 0:49:54
0:49:54
Transformer Encoder in 100 lines of code!
 1:13:26
1:13:26
PyTorch Implementation of Transformers
 3:34:41
3:34:41
[ 100k Special ] Transformers: Zero to Hero
 1:02:48
1:02:48
Lukasz Kaiser – Transformers - How Far Can They Go?
 1:15:52
1:15:52
Hands-On Workshop on Training and Using Transformers -- Kickoff Session
 0:18:46
0:18:46
GPT-1 | Paper Explained & PyTorch Implementation
 1:18:05
1:18:05
Lecture 20 - Efficient Transformers | MIT 6.S965
 1:03:38
1:03:38
Building with Pre-Trained BART, BERT, and GPT-Style LLMs
 1:03:21
1:03:21
【EP3】Large-Scale Visual Representation Learning with Vision Transformers
 1:03:30
1:03:30
Vision Transformer
 2:17:34
2:17:34
Deep Learning (Spring 2022) L5: Recurrent Neural Networks and Transformers
Комментарии