filmov
tv
Overview of Java 8 Parallel Streams (Part 1)
Показать описание
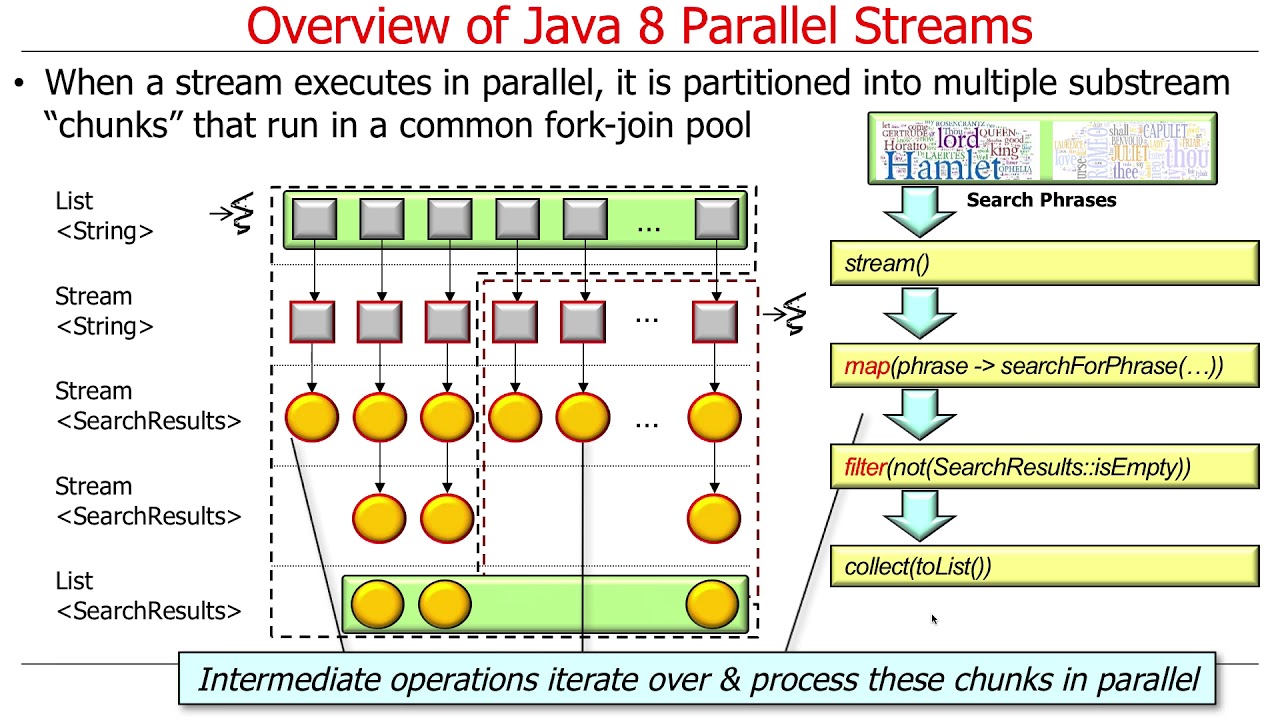
This video gives an overview of Java 8 parallel streams, giving an intro on how aggregate operations in a parallel stream work.
 0:17:16
0:17:16
Overview of Java 8 Parallel Streams (Part 1)
 0:16:49
0:16:49
Java 8 Parallel Streams | Parallel data processing and performance Example | JavaTechie
 0:12:39
0:12:39
Overview of Java 8 Parallel Streams (Part 1)
 0:13:34
0:13:34
Are You Using Java's Parallel Streams Correctly? - Java Programming
 0:08:46
0:08:46
Java8 - What is Parallel Stream|Sequential vs Parallel Stream|how to use parallel stream in java
 0:12:31
0:12:31
Overview of Java 8 Parallel Streams (Part 2)
 0:12:01
0:12:01
Introduction to Java 8 Concurrency and Parallelism Frameworks
 0:10:39
0:10:39
Overview of Parallel Programming in Java
 0:15:15
0:15:15
Overview of Java Parallelism Frameworks
 0:18:05
0:18:05
Introduction to Java 8 Parallelism Frameworks
 0:48:06
0:48:06
Parallel Streams, CompletableFuture, and All That: Concurrency in Java 8
 0:07:53
0:07:53
Introduction to Java 8 ParallelStream
 0:07:31
0:07:31
Overview of Java 8 Parallel Streams (Part 2a)
 0:47:48
0:47:48
Java 8 Parallel Streams (Parts 1 through 4)
 0:19:17
0:19:17
Java 8 Parallel Stream Internals (Part 1)
 0:10:30
0:10:30
Parallerl stream vs multi threads
 0:09:29
0:09:29
parallel stream vs sequential stream java 8
 0:15:22
0:15:22
Java 8 Parallel Streams Internals (Part 1)
 0:10:01
0:10:01
Issue with Parallel Streams in Java8 | What is Java Parallel Streams| When to use Parallel Stream
 0:38:31
0:38:31
Java 8 CompletableFuture Tutorial with Examples | runAsync() & supplyAsync() | JavaTechie | Pa...
 0:25:02
0:25:02
When to Use (and Not Use) Java 8 Parallel Streams
 0:20:31
0:20:31
Java Streams Part 7 - Parallel Streams | Hands-On
 0:30:14
0:30:14
Parallel Streams intro || Stream processing Interview Questions and Answers Java 8 | Code Decode
 0:03:55
0:03:55
How Parallel Streams Work in Java 8 | Java 8 Streams Explained | Java 8 streams | Streams in Java 8
Комментарии