filmov
tv
Pytorch RNN example (Recurrent Neural Network)
Показать описание
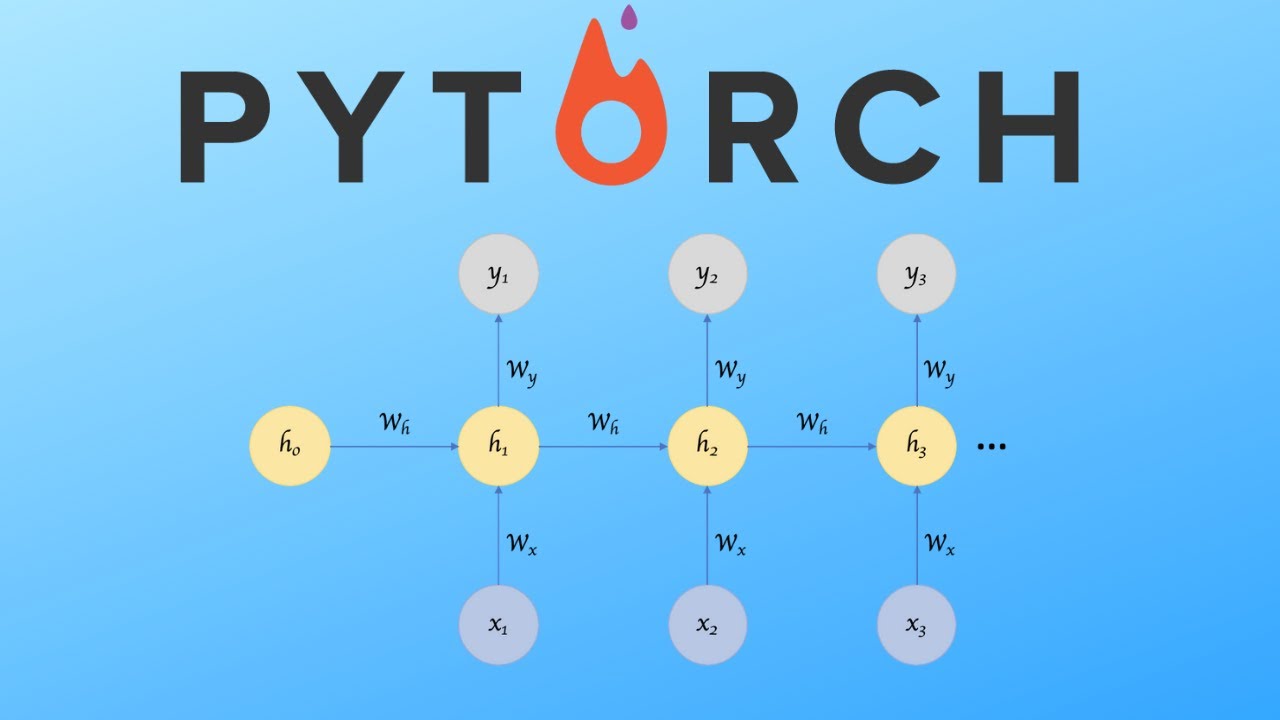
In this video we go through how to code a simple rnn, gru and lstm example. Focus is on the architecture itself rather than the data etc. and we use the simple MNIST dataset for this example.
❤️ Support the channel ❤️
Paid Courses I recommend for learning (affiliate links, no extra cost for you):
✨ Free Resources that are great:
💻 My Deep Learning Setup and Recording Setup:
GitHub Repository:
✅ One-Time Donations:
▶️ You Can Connect with me on:
❤️ Support the channel ❤️
Paid Courses I recommend for learning (affiliate links, no extra cost for you):
✨ Free Resources that are great:
💻 My Deep Learning Setup and Recording Setup:
GitHub Repository:
✅ One-Time Donations:
▶️ You Can Connect with me on:
 0:14:21
0:14:21
Pytorch RNN example (Recurrent Neural Network)
 0:38:57
0:38:57
PyTorch RNN Tutorial - Name Classification Using A Recurrent Neural Net
 0:15:52
0:15:52
PyTorch Tutorial - RNN & LSTM & GRU - Recurrent Neural Nets
 0:44:35
0:44:35
12. RNN. Recurrent Neural Network in PyTorch.
 0:15:00
0:15:00
MLfAS - 09 Recurrent Neural Networks (RNNs) - 06 Training the RNN in PyTorch
 0:10:43
0:10:43
Recurrent neural network example using surnames dataset | part 1 | Pytorch tutorial
 0:17:22
0:17:22
Recurrent Neural Networks with PyTorch
 0:10:26
0:10:26
Intro to recurrent neural network RNN | Pytorch tutorial
 2:03:43
2:03:43
Build a Simple Recurrent Neural Network Using PyTorch | Depth Analysis | Deep Learning | PyTorch
 0:44:59
0:44:59
Pytorch tutorial: Recurrent Neural Networks theory
 0:41:05
0:41:05
Machine Learning for Audio Signals in Python - 09 Recurrent Neural Networks (RNN) in PyTorch
 0:25:13
0:25:13
Recurrent Neural Network - Dall'architettura all'implementazione (RNN in PyTorch)
 0:20:33
0:20:33
Pytorch tutorial: Recurrent Neural Networks practice
 0:10:05
0:10:05
Recurrent neural network example using image dataset RNN | Pytorch tutorial
 0:40:00
0:40:00
L15.7 An RNN Sentiment Classifier in PyTorch
 0:16:37
0:16:37
Recurrent Neural Networks (RNNs), Clearly Explained!!!
 0:17:19
0:17:19
Pytorch for Beginners #21 | Recurrent Neural Networks: Understanding and Implementing Vanilla RNN
 0:11:08
0:11:08
Deep Learning Projects with PyTorch : Understanding Recurrent Neural Network | packtpub.com
 0:06:54
0:06:54
MLfAS - 09 Recurrent Neural Networks (RNNs) - 05 RNN as an IIR Generalization in PyTorch
 0:05:13
0:05:13
Hands-On Natural Language Processing with PyTorch:Work with Recurrent Neural Network| packtpub.com
 0:04:07
0:04:07
PyTorch Deep Learning in 7 Days: Recurrent Networks, RNN, and LSTM, GRU | packtpub.com
 0:52:51
0:52:51
RNN From Scratch In Python
 0:54:34
0:54:34
Lecture 19 - RNN Implementation
 0:10:43
0:10:43
How to Optimize an RNN in PyTorch (~20% to over 80% accuracy)
Комментарии