filmov
tv
Building a Pipeline for State-of-the-Art Natural Language Processing Using Hugging Face Tools

Показать описание
The natural language processing (NLP) landscape has radically changed with the arrival of transformer networks in 2017. From BERT to XLNet, ALBERT and ELECTRA, huge neural networks now manage to obtain unprecedented scores on benchmarks for tasks like sequence classification, question answering and named entity recognition. The pipeline from text to prediction remains complex, but tools like huggingface/transformers and huggingface/tokenizers take most of the burden off of the user, offering a simple API. This talk will focus on the entire NLP pipeline, from text to tokens with huggingface/tokenizers and from tokens to predictions with huggingface/transformers.
About:
Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
About:
Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
 0:48:47
0:48:47
Building a Pipeline for State-of-the-Art Natural Language Processing Using Hugging Face Tools
 0:22:00
0:22:00
Set Up a State of the Art Deployment Pipeline in 30 Minutes - React Native - April 2019
 0:00:14
0:00:14
Transformed an aging pipeline with our state-of-the-art pipelining technology!
 0:00:10
0:00:10
Pipeline Developer
 0:00:46
0:00:46
AI Pipeline Architecture Part 1
 0:22:36
0:22:36
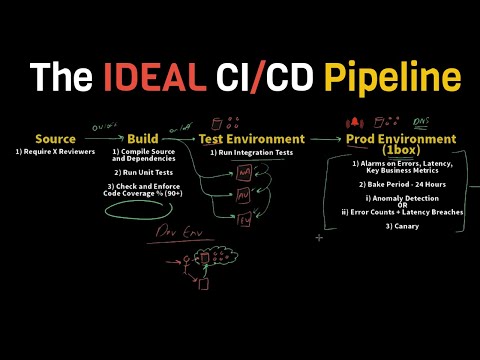
The IDEAL & Practical CI / CD Pipeline - Concepts Overview
 0:03:42
0:03:42
Atlantic Coast Pipeline - Viewshed Simulations
 0:02:59
0:02:59
LabelFusion: A Pipeline for Generating Ground Truth Labels for Real RGBD Data of Cluttered Scenes
 0:53:20
0:53:20
Gen AI Workflows for Video Games
 0:31:53
0:31:53
Fastest Automatic Firewood Processing Machine | Dangerous Big Chainsaw Cutting Tree machines #7
 0:00:21
0:00:21
Wee Trick for Contouring Pipes. Repost from @rorymcgeehan(TikTok) #yeswelder #shorts #pipeline #weld
 0:10:55
0:10:55
State of Creativity: Talent Pipeline | Artbound | KCET
 0:02:23
0:02:23
NVIDIA Cosmos: A World Foundation Model Platform for Physical AI
 0:01:01
0:01:01
Creating a Cutting-Edge RAG Pipeline with Llama 3.1 and NVIDIA NeMo Retriever NIMs | Srinivasan
 0:08:57
0:08:57
State of the Art – Future outlook on NMIBC – What’s in the pipeline
 0:01:53
0:01:53
Efficient Pipeline for Image Classification
 0:03:48
0:03:48
AUTOSTEM - Impressions of the fully automated pipeline for production of therapeutic stem cells
 0:00:54
0:00:54
Training on Piping codes & Standards | Piping design | Pipeline construction | Training course ...
 0:04:00
0:04:00
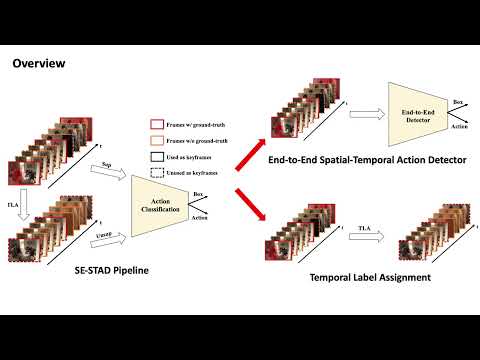
A Simple and Efficient Pipeline to Build an End-to-End Spatial-Temporal Action Detector
 0:19:29
0:19:29
Samantha Guerriero 'Building an end-to-end ML pipeline' GDG Cloud Ldn - open source is for...
 0:02:16
0:02:16
Pipeline Construction | Know Your Wisconsin
 0:05:17
0:05:17
Omnidata: A Scalable Pipeline for Making Multi-Task Mid-level Vision Datasets from 3D Scans
 0:00:16
0:00:16
Xindun Orbital Welding System: Mastering 78mm Pipeline Welding!
 0:01:23
0:01:23
Orbital Welding Machines for Chemical Industry Corrosion Resistant Pipeline Welding in Russia Europe
Комментарии