filmov
tv
Creating a Stream Data Pipeline on Google Cloud Platform using Apache Beam

Показать описание
We built a scalable and flexible stream data pipeline for our microservices on Google Cloud Platform (GCP), using Cloud Pub/Sub, Google Cloud Storage, BigQuery, and Cloud Dataflow, using Apache Beam. The stream data pipeline is working on the production system for Mercari, one of the biggest C2C e-commerce services in Japan. The pipeline currently accepts logs from 5+ microservices, and the number will increase soon.
Our microservice architecture is based on the following three concepts:
1. Split the log collection and data processing phases to keep the system simple.
2. Use stream processing in order to achieve low latency.
3. Don’t just accumulate raw data—support structured output that is easier to use.
For each microservice, we will provide a Cloud Pub/Sub “Ramp” to send logs to. Cloud Pub/Sub can have messages that contain an optional byte array in their payloads. The entire message that is ingested into the Ramp uses Cloud Dataflow streaming processing to collect them in the “RawDataHub,” a Cloud Pub/Sub topic for collection. When this happens, the PubsubMessage payload is not changed at all; the metadata necessary for subsequent processing (destination and schema information, data necessary for pipeline metrics, etc.) is provided in the PubsubMessage’s attribute map. This Dataflow job does not do processing for each service or topic—it treats all messages uniformly.The raw data from RawDataHub is then output to two independent Cloud DataFlow streaming processes: “RawDataLake”(the infrastructure is in Google Cloud Storage, or “GCS”) and “StructuredDataHub”, another Cloud Pub/Sub topic. The StructuredDataHub has structured avro records. The structured data from StructuredDataHub is then sent to more two independent Cloud DataFlow streaming processes: “StructuredDataLake” on GCS and “Data WareHouse” (Google BigQuery).
---
The Beam Summit North America 2019 was a 2-day event held in Las Vegas, all focused around Apache Beam.
Our microservice architecture is based on the following three concepts:
1. Split the log collection and data processing phases to keep the system simple.
2. Use stream processing in order to achieve low latency.
3. Don’t just accumulate raw data—support structured output that is easier to use.
For each microservice, we will provide a Cloud Pub/Sub “Ramp” to send logs to. Cloud Pub/Sub can have messages that contain an optional byte array in their payloads. The entire message that is ingested into the Ramp uses Cloud Dataflow streaming processing to collect them in the “RawDataHub,” a Cloud Pub/Sub topic for collection. When this happens, the PubsubMessage payload is not changed at all; the metadata necessary for subsequent processing (destination and schema information, data necessary for pipeline metrics, etc.) is provided in the PubsubMessage’s attribute map. This Dataflow job does not do processing for each service or topic—it treats all messages uniformly.The raw data from RawDataHub is then output to two independent Cloud DataFlow streaming processes: “RawDataLake”(the infrastructure is in Google Cloud Storage, or “GCS”) and “StructuredDataHub”, another Cloud Pub/Sub topic. The StructuredDataHub has structured avro records. The structured data from StructuredDataHub is then sent to more two independent Cloud DataFlow streaming processes: “StructuredDataLake” on GCS and “Data WareHouse” (Google BigQuery).
---
The Beam Summit North America 2019 was a 2-day event held in Las Vegas, all focused around Apache Beam.
 0:09:37
0:09:37
Data Pipelines: Introduction to Streaming Data Pipelines
 0:15:26
0:15:26
How to successfully launch a streaming data pipeline on Google Cloud
 0:07:50
0:07:50
Creating a Streaming Data Pipeline With Apache Kafka in 7 minutes
 0:04:55
0:04:55
Creating a Streaming Data Pipeline With Apache Kafka || #qwiklabs || #GSP730 | [With Explanation🗣️]...
 0:16:43
0:16:43
Create a Streaming Data Pipeline for Product Analytics
 0:19:09
0:19:09
Creating a Stream Data Pipeline on Google Cloud Platform using Apache Beam
 0:15:17
0:15:17
Building stream processing pipelines with Dataflow
 0:09:02
0:09:02
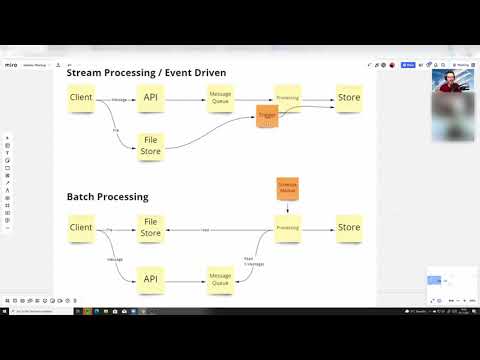
Stream vs Batch processing explained with examples
 1:38:04
1:38:04
Using vLLM to get an LLM running fast locally (live stream)
 0:05:25
0:05:25
What is Data Pipeline? | Why Is It So Popular?
 0:06:03
0:06:03
Imperva: Building Real-Time Streaming Data Pipelines Using Amazon MSK
 0:10:34
0:10:34
What is Data Pipeline | How to design Data Pipeline ? - ETL vs Data pipeline (2024)
 1:27:48
1:27:48
Realtime Data Streaming | End To End Data Engineering Project
 0:04:39
0:04:39
Creating a Streaming Data Pipeline With Apache Kafka || [GSP730] || Solution
 0:29:54
0:29:54
Building Realtime Data Pipelines with Kafka Connect and Spark Streaming
 0:29:45
0:29:45
Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline! by Robin Moffatt
 0:18:30
0:18:30
Creating a Streaming Data Pipeline With Apache Kafka GSP730
 0:08:29
0:08:29
Data Pipelines Explained
 0:52:43
0:52:43
Apache Kafka and KSQL in Action : Lets Build a Streaming Data Pipeline! by Viktor Gamov
 0:47:21
0:47:21
How to build stream data pipeline with Apache Kafka and Spark Structured Streaming - PyCon SG 2019
 0:40:57
0:40:57
Lab : Creating a Streaming Data Pipeline for a Real Time Dashboard with Dataflow
 0:28:43
0:28:43
Apache Kafka and ksqlDB in Action: Let's Build a Streaming Data Pipeline!
 1:25:00
1:25:00
Building a Real-Time Data Streaming Pipeline using Apache Kafka, Flink and Postgres
 0:34:44
0:34:44
GCP Lab 2 - Creating a Streaming Data Pipeline with DataFlow
Комментарии