filmov
tv
Neural networks [5.4] : Restricted Boltzmann machine - contrastive divergence

Показать описание
![Neural networks [5.1]](https://i.ytimg.com/vi/p4Vh_zMw-HQ/hqdefault.jpg) 0:12:17
0:12:17
Neural networks [5.1] : Restricted Boltzmann machine - definition
 0:12:12
0:12:12
Restricted Boltzmann Machine | Neural Network Tutorial | Deep Learning Tutorial | Edureka
![Neural networks [5.3]](https://i.ytimg.com/vi/e0Ts_7Y6hZU/hqdefault.jpg) 0:12:54
0:12:54
Neural networks [5.3] : Restricted Boltzmann machine - free energy
 0:18:40
0:18:40
But what is a neural network? | Chapter 1, Deep learning
 0:01:07
0:01:07
Restricted Boltzmann Machines in 60 seconds!
 0:08:56
0:08:56
Introduction to Boltzmann Machines
![[4/5] Rémi Monasson](https://i.ytimg.com/vi/mAc7zP64z2o/hqdefault.jpg) 1:42:16
1:42:16
[4/5] Rémi Monasson (2018) Unsupervised neural networks: from theory to systems biology
 0:01:58
0:01:58
Deep Neural Network
![Neural networks [5.5]](https://i.ytimg.com/vi/wMb7cads0go/hqdefault.jpg) 0:11:10
0:11:10
Neural networks [5.5] : Restricted Boltzmann machine - contrastive divergence (parameter update)
 0:05:25
0:05:25
An Old Problem - Ep. 5 (Deep Learning SIMPLIFIED)
 0:04:56
0:04:56
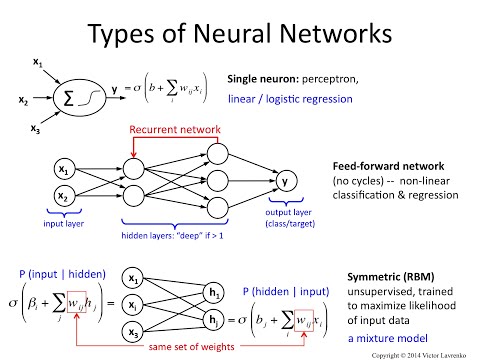
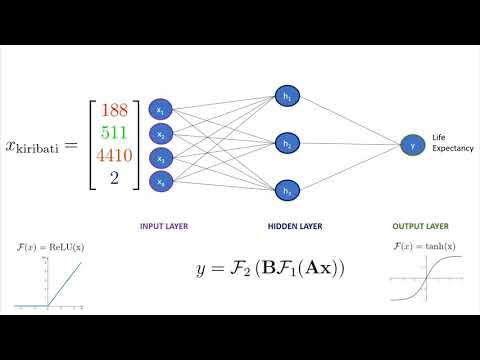
Neural Networks 5: feedforward, recurrent and RBM
 0:05:32
0:05:32
Deep Neural Network (DNN) | Deep Learning
 0:00:58
0:00:58
The Boltzmann Machine – The Most Important Energy-Based Neural Network #shorts
 0:36:58
0:36:58
Restricted Boltzmann Machines (RBM) - A friendly introduction
 0:16:10
0:16:10
Deep Learning Part - II (CS7015): Lec 18.3 Restricted Boltzmann Machines
 0:01:56
0:01:56
Deep Neural Network Introduction
 0:00:46
0:00:46
NEVER buy from the Dark Web.. #shorts
 0:03:54
0:03:54
Feed Forward Network In Artificial Neural Network Explained In Hindi
 0:07:34
0:07:34
What is a Neural Network | Neural Networks Explained in 7 Minutes | Edureka
 1:20:43
1:20:43
Lecture 15 | (4/5) Recurrent Neural Networks
 1:05:53
1:05:53
Applied Deep Learning 2022 - Lecture 4 - Recurrent Neural Networks
![Neural networks [9.10]](https://i.ytimg.com/vi/y0SISi_T6s8/hqdefault.jpg) 0:10:46
0:10:46
Neural networks [9.10] : Computer vision - convolutional RBM
 0:05:34
0:05:34
Attention mechanism: Overview
 0:20:33
0:20:33
Gradient descent, how neural networks learn | Chapter 2, Deep learning
Комментарии