filmov
tv
Everyday Probabilistic Data Structures for Humans

Показать описание
Processing large amounts of data for analytical or business cases is a daily occurrence for Apache Spark users. Cost, Latency and Accuracy are 3 sides of a triangle a product owner has to trade off. When dealing with TBs of data a day and PBs of data overall, even small efficiencies have a major impact on the bottom line. This talk is going to talk about practical application of the following 4 data-structures that will help design an efficient large scale data pipeline while keeping costs at check.
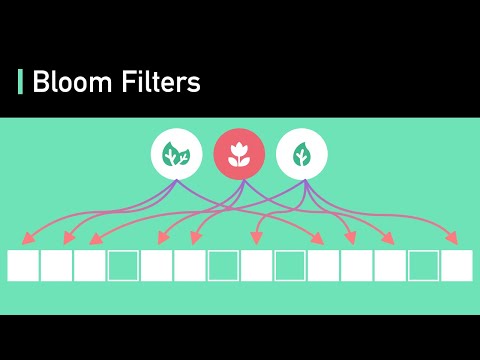
1. Bloom Filters
2. Hyper Log Log
3. Count-Min Sketches
4. T-digests (Bonus)
We will take the fictional example of an eCommerce company Rainforest Inc and try to answer the business questions with our PDT and Apache Spark and and not do any SQL for this.
1. Has User John seen an Ad for this product yet?
2. How many unique users bought Items A , B and C
3. Who are the top Sellers today?
4. Whats the 90th percentile of the cart Prices? (Bonus)
We will dive into how each of these data structures are calculated for Rainforest Inc and see what operations and libraries will help us achieve our results. The session will simulate a TB of data in a notebook (streaming) and will have code samples showing effective utilizations of the techniques described to answer the business questions listed above. For the implementation part we will implement the functions as Structured Streaming Scala components and Serialize the results to be queried separately to answer our questions. We would also present the cost and latency efficiencies achieved at the Adobe Experience Platform running at PB Scale by utilizing these techniques to showcase that it goes beyond theory.
About:
Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
1. Bloom Filters
2. Hyper Log Log
3. Count-Min Sketches
4. T-digests (Bonus)
We will take the fictional example of an eCommerce company Rainforest Inc and try to answer the business questions with our PDT and Apache Spark and and not do any SQL for this.
1. Has User John seen an Ad for this product yet?
2. How many unique users bought Items A , B and C
3. Who are the top Sellers today?
4. Whats the 90th percentile of the cart Prices? (Bonus)
We will dive into how each of these data structures are calculated for Rainforest Inc and see what operations and libraries will help us achieve our results. The session will simulate a TB of data in a notebook (streaming) and will have code samples showing effective utilizations of the techniques described to answer the business questions listed above. For the implementation part we will implement the functions as Structured Streaming Scala components and Serialize the results to be queried separately to answer our questions. We would also present the cost and latency efficiencies achieved at the Adobe Experience Platform running at PB Scale by utilizing these techniques to showcase that it goes beyond theory.
About:
Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
 0:39:51
0:39:51
 0:33:38
0:33:38
 0:39:11
0:39:11
 0:32:46
0:32:46
 0:54:50
0:54:50
 0:39:12
0:39:12
 0:58:30
0:58:30
 1:01:30
1:01:30
 0:04:34
0:04:34
 0:05:40
0:05:40
 0:25:45
0:25:45
 0:45:44
0:45:44
 0:31:11
0:31:11
 1:17:46
1:17:46
 0:00:59
0:00:59
 0:21:47
0:21:47
 0:38:29
0:38:29
 0:35:36
0:35:36
 0:28:09
0:28:09
 0:31:11
0:31:11
 0:05:10
0:05:10
 1:00:25
1:00:25
 0:11:30
0:11:30
 0:19:33
0:19:33