filmov
tv
ComfyUI SDXL Basic Setup Part 3
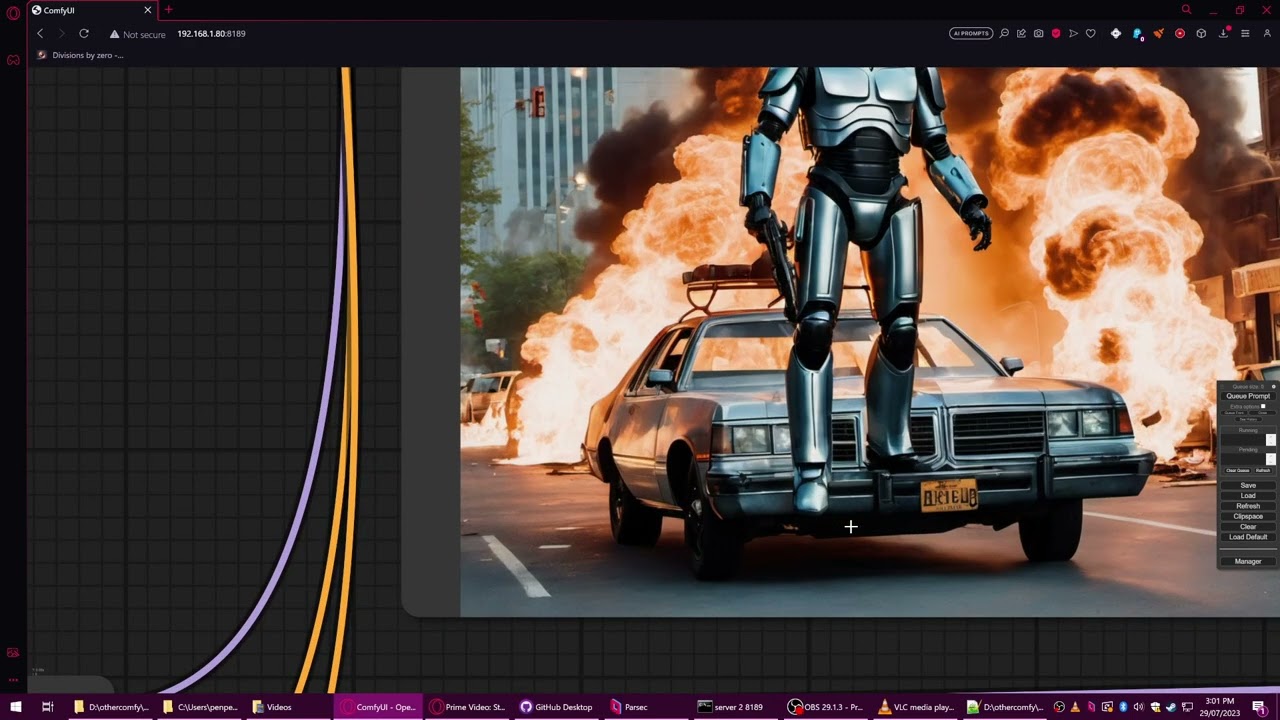
Показать описание
A barebones basic way of setting up SDXL
Requires:
ComfyUI manager (for easiest way of finding custom nodes)
WAS suite
Derfuu's Math Nodes
Quality of life suite
Requires:
ComfyUI manager (for easiest way of finding custom nodes)
WAS suite
Derfuu's Math Nodes
Quality of life suite
 0:13:05
0:13:05
ComfyUI SDXL Basic Setup Part 1
 0:25:26
0:25:26
ComfyUI SDXL Basic Setup Part 2
 0:16:44
0:16:44
SDXL ComfyUI Stability Workflow - What I use internally at Stability for my AI Art
 0:37:43
0:37:43
ComfyUI SDXL Basic Setup Part 4 - upgrading your workflow
 0:25:59
0:25:59
ComfyUI SDXL Basic Setup Part 3
 0:22:27
0:22:27
Run SDXL Locally With ComfyUI (2024 Stable Diffusion Guide)
 0:04:40
0:04:40
ComfyUI 01- Install and run SDXL is Super Easy
 1:04:03
1:04:03
Beginner's Guide to Stable Diffusion and SDXL with COMFYUI
 0:11:05
0:11:05
ComfyUI - Change Character Outfit with Magic Clothing
 0:14:09
0:14:09
How to Install ComfyUI in 2023 - Ideal for SDXL!
 0:17:34
0:17:34
ComfyUI SDXL Advanced Setup Part 5 - Adv dual sampler
 0:15:14
0:15:14
L1: Using ComfyUI, EASY basics - Comfy Academy
 0:47:42
0:47:42
ComfyUI Tutorial - How to Install ComfyUI on Windows, RunPod & Google Colab | Stable Diffusion S...
 0:53:24
0:53:24
ComfyUI for Stable Diffusion Tutorial (Basics, SDXL & Refiner Workflows)
 0:19:01
0:19:01
ComfyUI - Getting Started : Episode 1 - Better than AUTO1111 for Stable Diffusion AI Art generation
 0:12:45
0:12:45
How to install and use ComfyUI - Stable Diffusion.
 0:15:59
0:15:59
ComfyUI : NEW Official ControlNet Models are released! Here is my tutorial on how to use them.
 0:09:28
0:09:28
ComfyUI - Getting Started : Episode 2 - Custom Nodes Everyone Should Have
 0:15:03
0:15:03
ComfyUI Workflow Creation Essentials For Beginners
 0:07:39
0:07:39
SDXL ComfyUI img2img - A simple workflow for image 2 image (img2img) with the SDXL diffusion model
 0:07:08
0:07:08
How to Install SDXL Base 0.9 and Run with ComfyUi Easy Steps | Beginners Guide.
 0:11:17
0:11:17
How To Install ComfyUI and Run SDXL on Low GPUs
 0:05:24
0:05:24
The Easiest ComfyUI Workflow With Efficiency Nodes
 0:10:25
0:10:25
NEW SDXL ComfyUI controlnet Installation and Workflow models
Комментарии