filmov
tv
3 Key Version Control Mistakes (HUGE STEP BACKWARDS)

Показать описание
Version Control is pervasive these days, and is fundamental to professional software development, but where does it go next? Git, often via platforms like GitHub, GitLab or BitBucket, is by far the most popular VCS, but its value is being watered down, and the next steps in software development, look to be ignoring this vital tool of software engineering. Without the ability to step back safely from mistakes, and re-establish "known-good" starting points from Version Control, we will loose the ability to make incremental progress, and with that loss, we also loose the ability to create truly complex systems.
In this episode Dave Farley, author of best sellers "Continuous Delivery" and "Modern Software Engineering" describes that essential role of version control, that we often ignore, and explores 3 ways in which we often compromise the value and utility of version control in our software projects.
-
🖇 LINKS:
-
⭐ PATREON:
-
👕 T-SHIRTS:
A fan of the T-shirts I wear in my videos? Grab your own, at reduced prices EXCLUSIVE TO CONTINUOUS DELIVERY FOLLOWERS! Get money off the already reasonably priced t-shirts!
🚨 DON'T FORGET TO USE THIS DISCOUNT CODE: ContinuousDelivery
-
BOOKS:
and NOW as an AUDIOBOOK available on iTunes, Amazon and Audible.
📖 "Continuous Delivery Pipelines" by Dave Farley
NOTE: If you click on one of the Amazon Affiliate links and buy the book, Continuous Delivery Ltd. will get a small fee for the recommendation with NO increase in cost to you.
-
CHANNEL SPONSORS:
#softwareengineer #developer #git #github #versioncontrol
In this episode Dave Farley, author of best sellers "Continuous Delivery" and "Modern Software Engineering" describes that essential role of version control, that we often ignore, and explores 3 ways in which we often compromise the value and utility of version control in our software projects.
-
🖇 LINKS:
-
⭐ PATREON:
-
👕 T-SHIRTS:
A fan of the T-shirts I wear in my videos? Grab your own, at reduced prices EXCLUSIVE TO CONTINUOUS DELIVERY FOLLOWERS! Get money off the already reasonably priced t-shirts!
🚨 DON'T FORGET TO USE THIS DISCOUNT CODE: ContinuousDelivery
-
BOOKS:
and NOW as an AUDIOBOOK available on iTunes, Amazon and Audible.
📖 "Continuous Delivery Pipelines" by Dave Farley
NOTE: If you click on one of the Amazon Affiliate links and buy the book, Continuous Delivery Ltd. will get a small fee for the recommendation with NO increase in cost to you.
-
CHANNEL SPONSORS:
#softwareengineer #developer #git #github #versioncontrol
 0:15:08
0:15:08
3 Key Version Control Mistakes (HUGE STEP BACKWARDS)
 0:07:02
0:07:02
How to Maintain Document Version Control on Your Project
 0:04:34
0:04:34
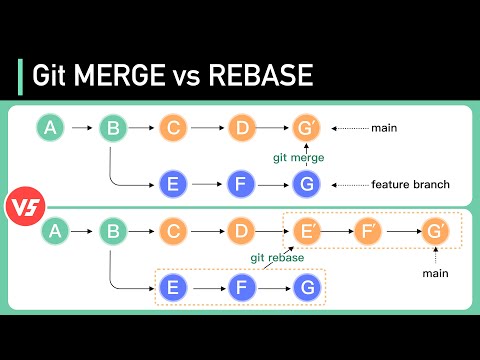
Git MERGE vs REBASE: Everything You Need to Know
 0:07:16
0:07:16
What Is Version Control? | Git Version Control | Version Control In Software Engineering|Simplilearn
 0:01:00
0:01:00
Nesting 'If Statements' Is Bad. Do This Instead.
 0:00:35
0:00:35
How to exit Git Bash commit message window in Windows
 0:05:55
0:05:55
What is Version Control and why you should ALWAYS use it | 2022
 0:27:10
0:27:10
What’s Wrong With Git? - Git Merge 2017
 0:13:04
0:13:04
Versioning Data with DVC (Hands-On Tutorial!)
 0:08:21
0:08:21
Version control & project organization best practices
 0:00:30
0:00:30
Unity Input System Error Fix Under 40 Seconds
 0:00:28
0:00:28
Developer Last Expression 😂 #shorts #developer #ytshorts #uiux #python #flutterdevelopment
 0:30:15
0:30:15
Git Tutorial with Python p.1 – Key Concepts (Version Control, Commits, Branches, Remote Repo etc.)
 0:03:41
0:03:41
gitignore in Visual Studio Code
 0:01:16
0:01:16
The Git repository has too many active changes || VS Code
 0:13:17
0:13:17
Git Interview Questions | Git Real-Time Interview Questions & Answers | DevOps Tools | Simplilea...
 0:01:57
0:01:57
3 Key Mistakes to Avoid on Your Financial Freedom Journey
 0:04:30
0:04:30
How to Completely Remove .env/secrets File from Github Repository When Pushed By Mistake
 0:53:23
0:53:23
TechSession: A Crash Course in Version Control and Git with Warren Frame
 0:00:27
0:00:27
How to set Tabs in Word
 0:04:20
0:04:20
Word: Track Changes and Comments
 0:08:16
0:08:16
5 Github Hacks that you should know | for Coders
 0:08:46
0:08:46
8 Mistakes Beginner Programmers Make
 0:02:43
0:02:43
What is GitHub?
Комментарии