filmov
tv
How to handle max request limits when web scraping with Python requests library

Показать описание
This video will cover how to handle max requests limits on websites when web scraping with Python requests library. We show how to use HTTPAdaptor and urllib's Retry objects to automatically try again and slow down the requests.
 0:00:59
0:00:59
How to handle max request limits when web scraping with Python requests library
 0:13:33
0:13:33
How to control the Request Payload Size in Nginx | Client Max Body Size | Request Entity Too Large
 0:01:23
0:01:23
Samsung Galaxy S22 Ultra : How to set Autofill Max request per session
 0:11:06
0:11:06
5 Biggest Mistakes All Noobs Make in Clash of Clans
 0:01:54
0:01:54
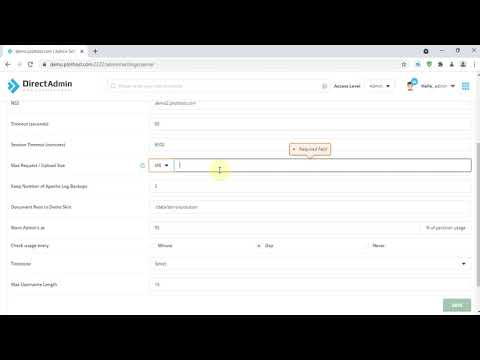
How to increase the DirectAdmin File Manager Max Request / Upload Size
 0:09:24
0:09:24
ProviderError: max code size exceeded at HttpProvider.request
 0:00:38
0:00:38
Request desktop website mode in safari iPhone 13 Pro Max || part 37 || #iphone #shorts #shortvideo
 0:06:21
0:06:21
iOS 18.1 - Do This IMMEDIATELY After You Update!
 0:01:32
0:01:32
iPhone 14's/14 Pro Max: How to Turn On/Off Request Desktop Website for All Websites In Safari
 0:07:42
0:07:42
How to Negotiate Salary after Job Offer | 5 Practical Tips
 0:05:37
0:05:37
Setup for Isometric rendering - 3ds max [ Request ]
 0:08:56
0:08:56
iOS 18.1 (Apple Intelligence) First Things To Do!
 0:00:59
0:00:59
iPhone 14/14 Pro Max: How to Turn On/Off Request From Contacts Only In Game Center
 0:02:04
0:02:04
Choose between the different eDrive modes – BMW How-To
 0:02:15
0:02:15
3ds Max - Freezing a Simulation (Request)
 0:01:04
0:01:04
iPhone 15/15 Pro Max: How to Allow/Block Apps To Request To Use Personal Voice
 0:08:37
0:08:37
Advanced SQL Tutorial | Subqueries
 0:00:20
0:00:20
Life Is Strange Swimming Pool Max Chloe (fan request)
 0:01:43
0:01:43
Line Handling Accident Prevention
 0:00:14
0:00:14
Black hole vs the nebula #mad-max #request #wod #shorts
 0:00:21
0:00:21
PHARAOH SET FULL MAX ]]] SEND ME FRIEND REQUEST|| BGMI. || RAGON TOSS
 0:00:46
0:00:46
How To Enable iMessage On iPhone | Tech Insider
 0:11:44
0:11:44
How to RAISE Your Credit Score Quickly (Guaranteed!)
 0:07:34
0:07:34
Diwali Magic Cube Kaise Milega? How to Claim Free Magic Cube | Magic Cube Mission Free Fire
Комментарии