filmov
tv
Principal Component Analysis (PCA) [Matlab]

Показать описание
This video describes how the singular value decomposition (SVD) can be used for principal component analysis (PCA) in Matlab.
These lectures follow Chapter 1 from: "Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control" by Brunton and Kutz
This video was produced at the University of Washington
These lectures follow Chapter 1 from: "Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control" by Brunton and Kutz
This video was produced at the University of Washington
 0:09:21
0:09:21
Principal Component Analysis (PCA) | MATLAB | Machine Learning
 0:34:19
0:34:19
Principal Component Analysis (PCA) using MATLAB | MATLAB Tutorial for Beginners | Simplilearn
 0:15:56
0:15:56
Principal Component Analysis (PCA) [Matlab]
 0:05:24
0:05:24
Doing Principal Components Analysis in Matlab - using the pca function (Statistics Toolbox)
 0:05:33
0:05:33
Principal Component Analysis in MATLAB
 0:04:00
0:04:00
PCA in matlab ( Principal Component analysis in Matlab)
 0:21:22
0:21:22
Calculating Principal component analysis (PCA), step by step using a simple dataset.
 0:13:46
0:13:46
Principal Component Analysis (PCA)
 0:10:09
0:10:09
Principal Component Analysis (PCA) in MATLAB
 0:10:56
0:10:56
Principal Component Analysis (PCA) - easy and practical explanation
 0:06:05
0:06:05
StatQuest: PCA main ideas in only 5 minutes!!!
 0:03:11
0:03:11
Principle Component Analysis Matlab Tutorial Part 1 - Overview
 0:05:25
0:05:25
MATLAB tutorial - principal component analysis (PCA)
 1:20:08
1:20:08
Principal Component Analysis (PCA) in Python and MATLAB
 0:00:56
0:00:56
MATLAB CODE for FACE RECOGNITION using Principal Component Analysis PCA
 0:03:11
0:03:11
Face recognition using Principal Component Analysis(PCA) in Matlab - Part 2.2( II )
 0:09:36
0:09:36
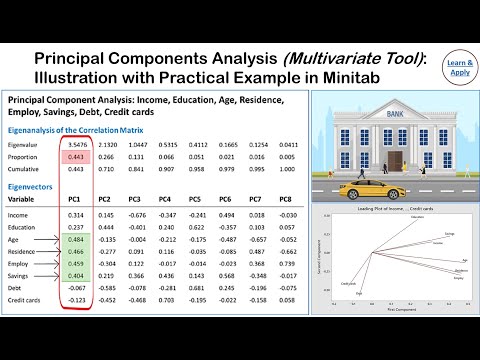
Principal Component Analysis (PCA): With Practical Example in Minitab
 0:09:27
0:09:27
Understand & interpret result of pca MATLAB | Machine Learning
 0:06:32
0:06:32
Principal Component Analysis - Theory & MATLAB Implementation | Machine Learning | @MATLABHelper
 0:20:09
0:20:09
Data Analysis 6: Principal Component Analysis (PCA) - Computerphile
 0:12:18
0:12:18
MATLAB tutorial: Principal Component Analysis & Regression
 0:13:40
0:13:40
Principal Component Analysis (PCA) Intuition | Machine Learning
 0:13:41
0:13:41
Principal Component Analysis- Part I
 0:02:36
0:02:36
PCA using MATLAB: Simplify Data Insights #PCA #matlabtutorial
Комментарии