filmov
tv
Spark Scenario Based Question | Alternative to df.count() | Use Case For Accumulators | learntospark

Показать описание
In this video, we will discuss about the scenario based question on Spark. We will see an alternative method to find the count of dataframe in Spark application. We will learn about the use case for accumulator using this Demo.
DataSet:
Blog link to learn more on Spark:
Linkedin profile:
FB page:
DataSet:
Blog link to learn more on Spark:
Linkedin profile:
FB page:
 0:06:01
0:06:01
49. Databricks & Spark: Interview Question(Scenario Based) - How many spark jobs get created?
 0:39:46
0:39:46
10 PySpark Product Based Interview Questions
 0:08:13
0:08:13
Spark Interview Question | Scenario Based Question | Multi Delimiter | LearntoSpark
 0:03:58
0:03:58
1. Merge two Dataframes using PySpark | Top 10 PySpark Scenario Based Interview Question|
 0:24:17
0:24:17
pyspark scenario based interview questions and answers | #pyspark | #interview | #data
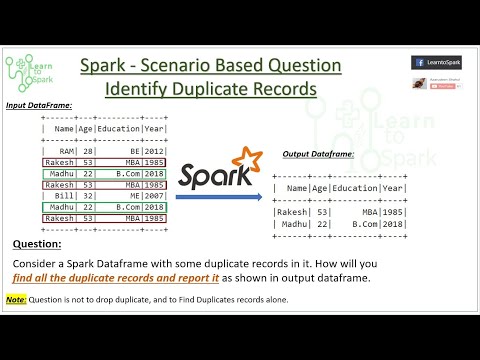 0:06:56
0:06:56
Spark Scenario Based Question | Window - Ranking Function in Spark | Using PySpark | LearntoSpark
 0:05:09
0:05:09
Spark Interview Question | Scenario Based | Data Masking Using Spark Scala | With Demo| LearntoSpark
 0:07:01
0:07:01
Spark Scenario Based Interview Question | Missing Code
 0:07:05
0:07:05
40 Scenario based pyspark interview question | pyspark interview
 0:13:03
0:13:03
Spark Scenario Based Question | Use Case on Drop Duplicate and Window Functions | LearntoSpark
 0:07:51
0:07:51
Spark SQL Greatest and Least Function - Apache Spark Scenario Based Questions | Using PySpark
 0:05:19
0:05:19
Spark Scenario Based Question | Best Way to Find DataFrame is Empty or Not | with Demo| learntospark
 0:13:59
0:13:59
Spark Scenario Based Question | ClickStream Analytics
 0:06:43
0:06:43
Coalesce in Spark SQL | Scala | Spark Scenario based question
 0:05:55
0:05:55
Comparing Lists in Scala | Spark Interview Questions | Realtime scenario
 0:04:30
0:04:30
Spark Scenario Based Question | Alternative to df.count() | Use Case For Accumulators | learntospark
 0:07:09
0:07:09
Spark Scenario Based Question | Handle JSON in Apache Spark | Using PySpark | LearntoSpark
 0:14:16
0:14:16
question 2 : spark scenario based interview question and answer | spark architecture?
 0:08:22
0:08:22
Spark Scenario Based Question | Deal with Ambiguous Column in Spark | Using PySpark | LearntoSpark
 0:08:54
0:08:54
question 1 : spark scenario based interview question and answer | spark vs hadoop mapreduce
 0:10:23
0:10:23
Spark Scenario Based Question | SET Operation Vs Joins in Spark | Using PySpark | LearntoSpark
 0:18:11
0:18:11
day 3 | consecutive days | pyspark scenario based interview questions and answers
 0:07:38
0:07:38
Spark Scenario Based Question | Dealing with Date in PySpark | Beginner's Guide | LearntoSpark
 0:12:05
0:12:05
question 3 (part - 2) : spark scenario based interview question and answer | spark terminologies
Комментарии